Latest issue
The SLO You Set in a Conference Room Will Lie to You in Production
8/2/2026
There's a particular kind of meeting that happens at most engineering organizations, usually sometime in Q1 or after a bad incident. Someone pulls up a blank doc, types "Service Level Objectives," and the room starts negotiating. By the end of an hour, you have numbers. Four nine…
Recent posts
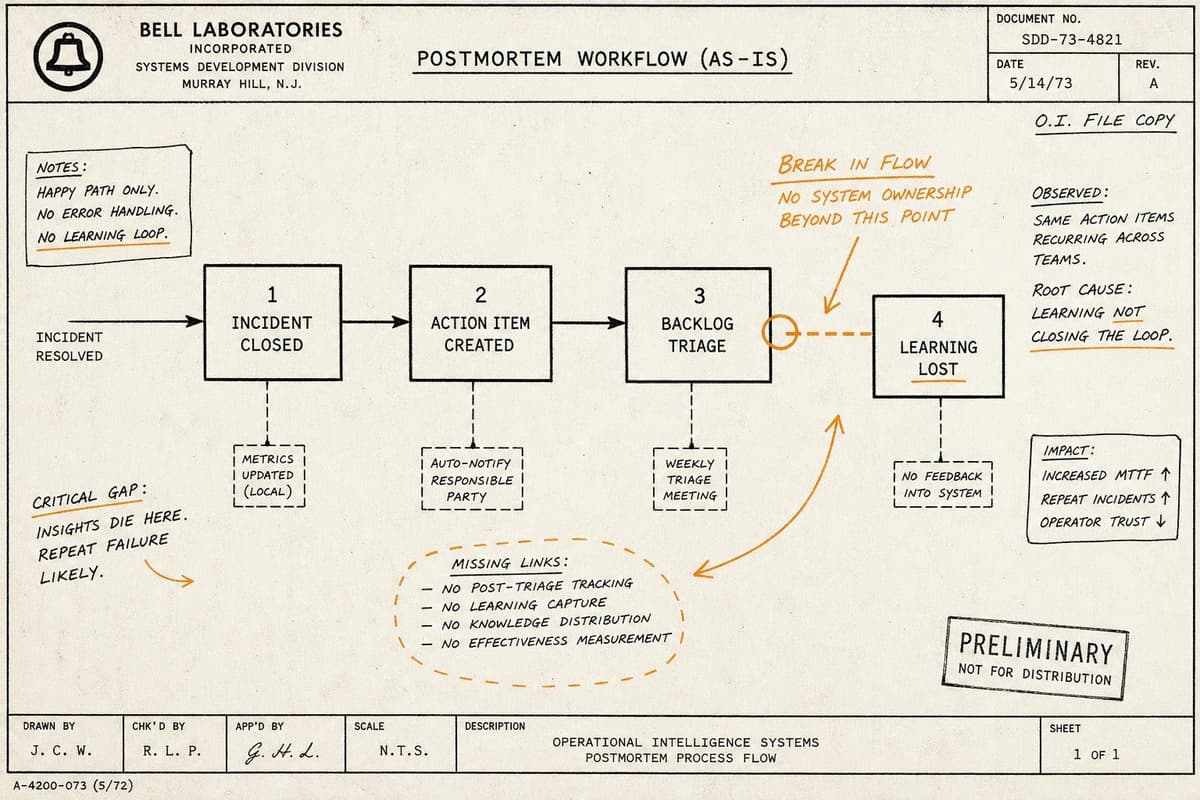
The postmortem is filed. The action items are in Jira. Someone marked the incident resolved at 4:17am and went back to sleep. By Monday morning, the ticket has a due date three spr…
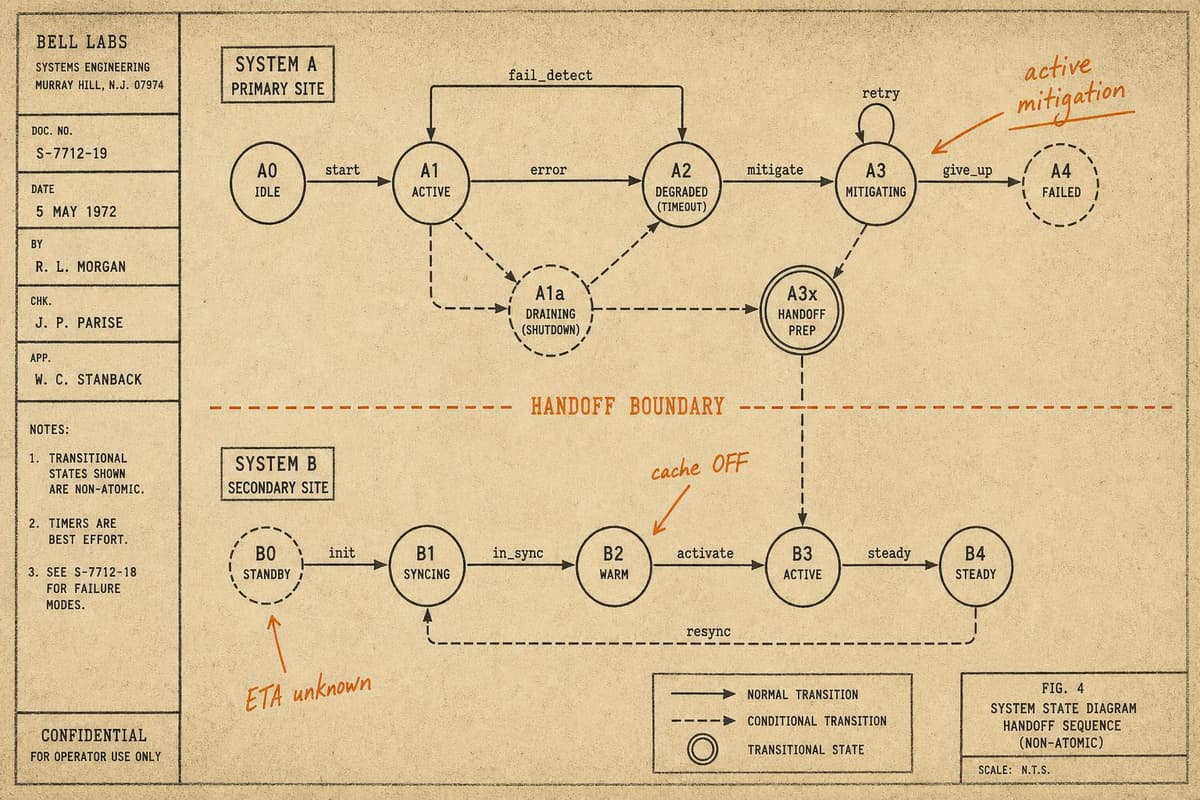
You've tested your rollback procedure. You've run game days. You've validated that your alerting fires within thirty seconds of a threshold breach. What you probably haven't tested…
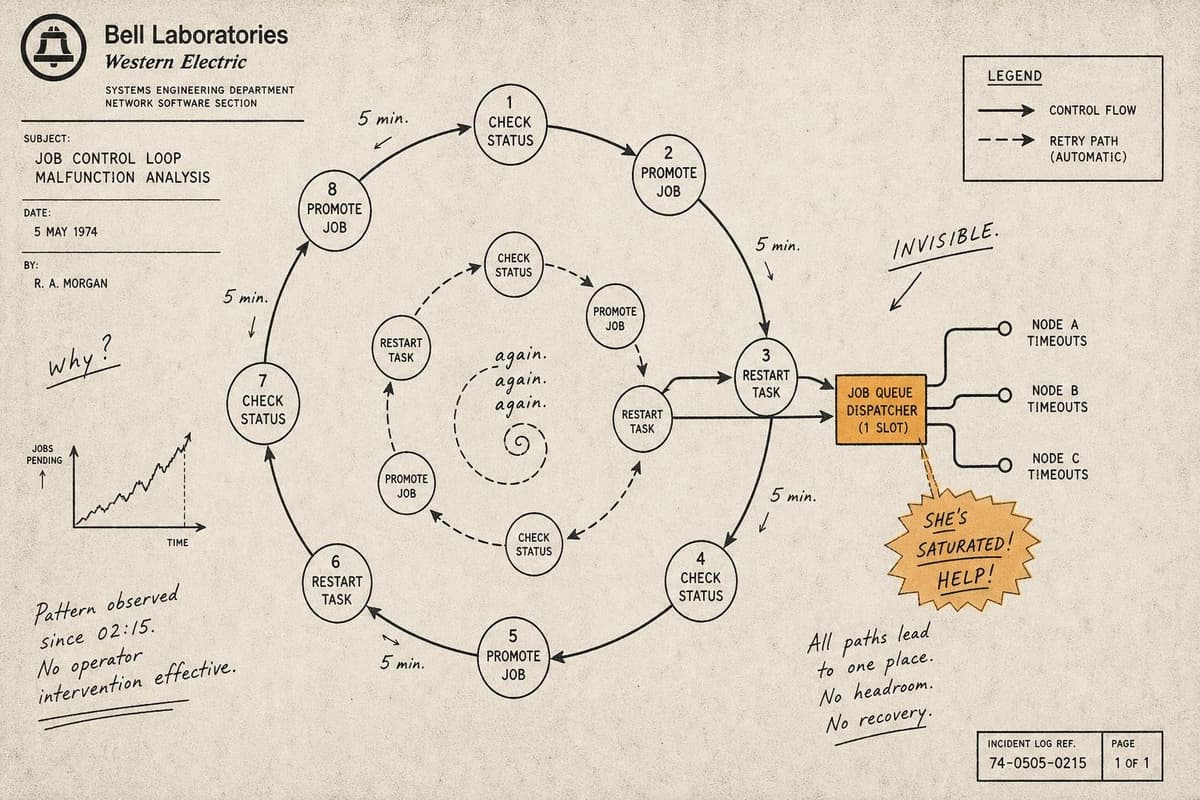
Somewhere on your team right now, someone is doing something for the third time this week that they've done a hundred times before. Restarting a service. Manually promoting a confi…
You schedule the chaos experiment for Tuesday at 2pm. You kill a pod. The system recovers. You write "resilience validated" in the ticket and close it. Three weeks later, a real fa…
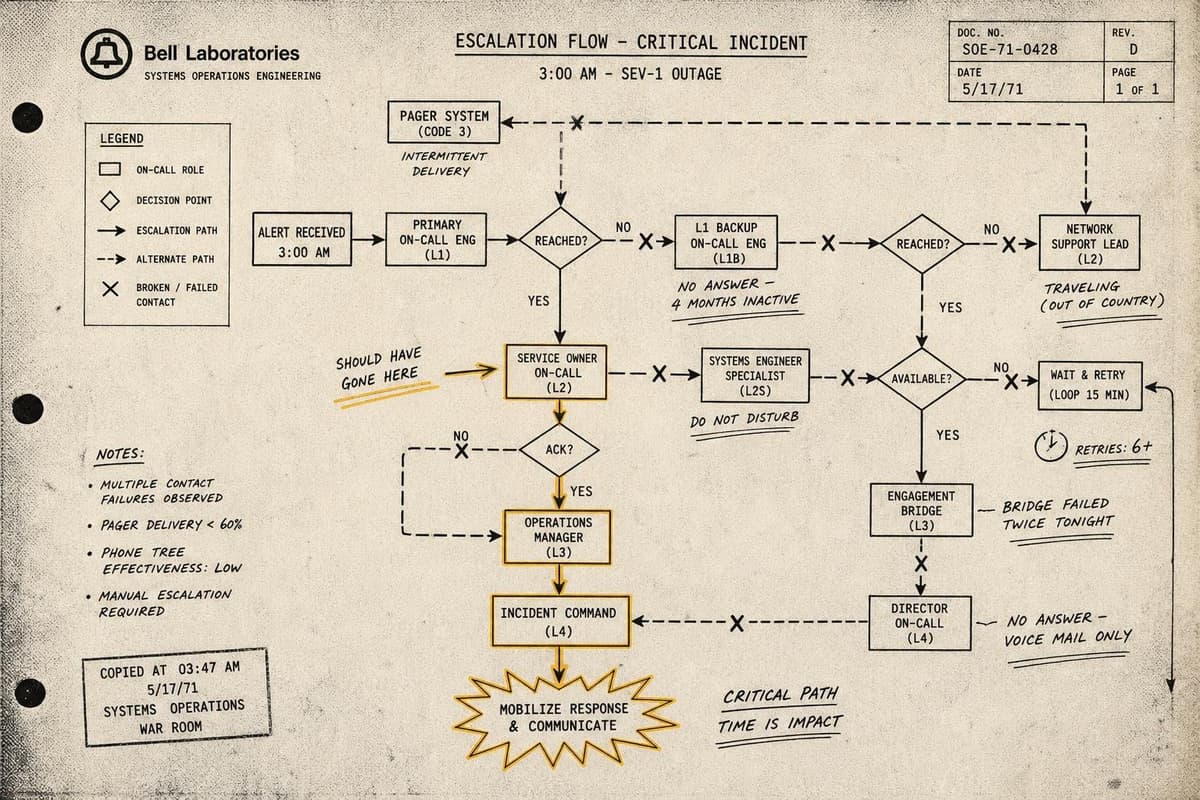
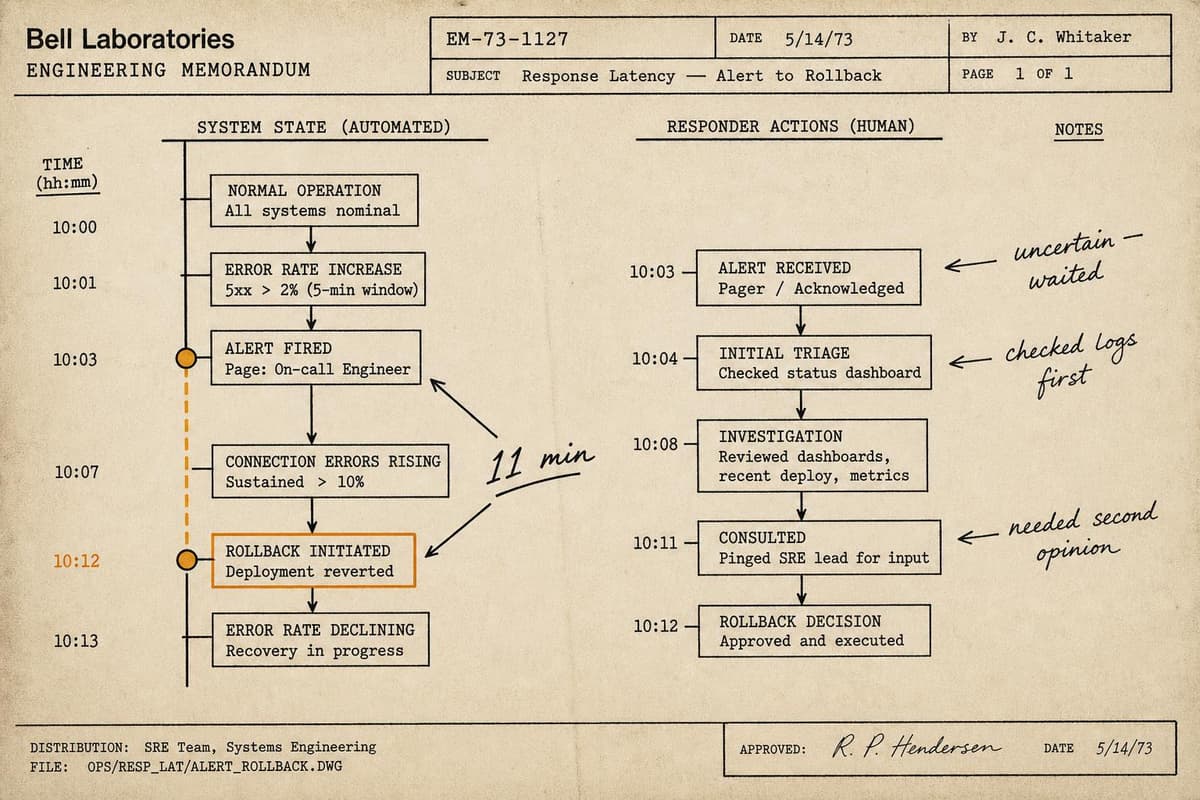
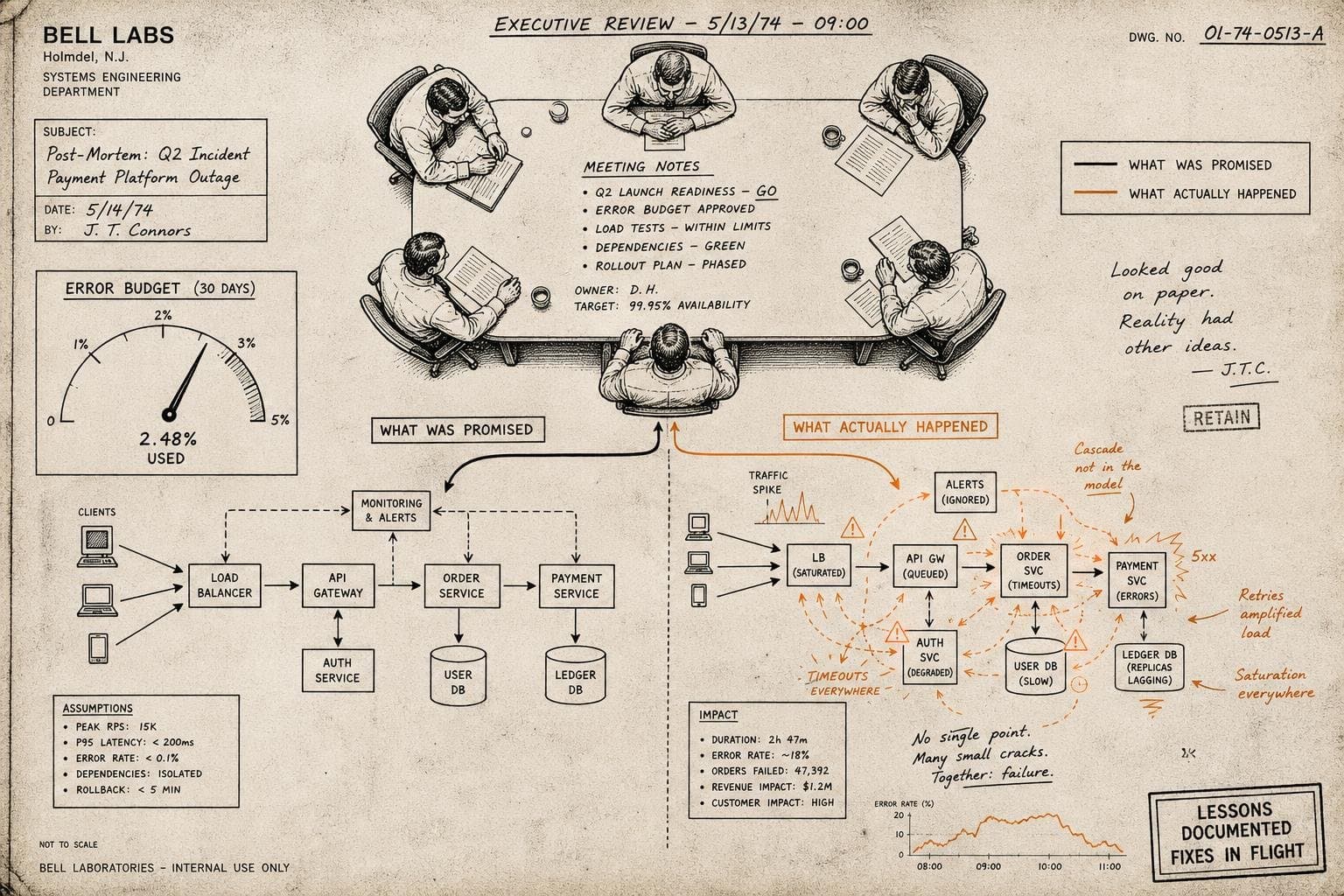
The pager fires at 2:47am. Within ninety seconds, three engineers are awake and in the incident channel. Someone starts checking dashboards. Someone else begins restarting services…
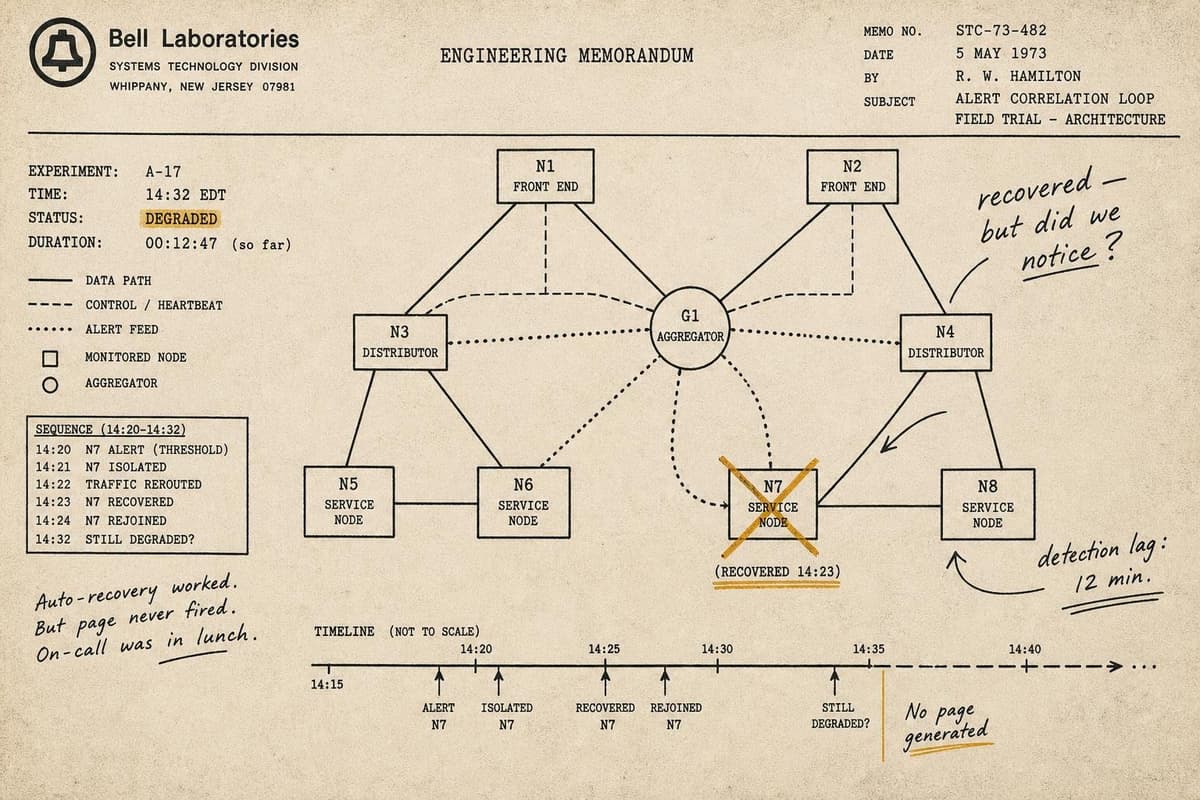
There's a particular kind of operational irony that only reveals itself at 2am: the team spent three months building a beautiful observability dashboard, and when the incident actu…
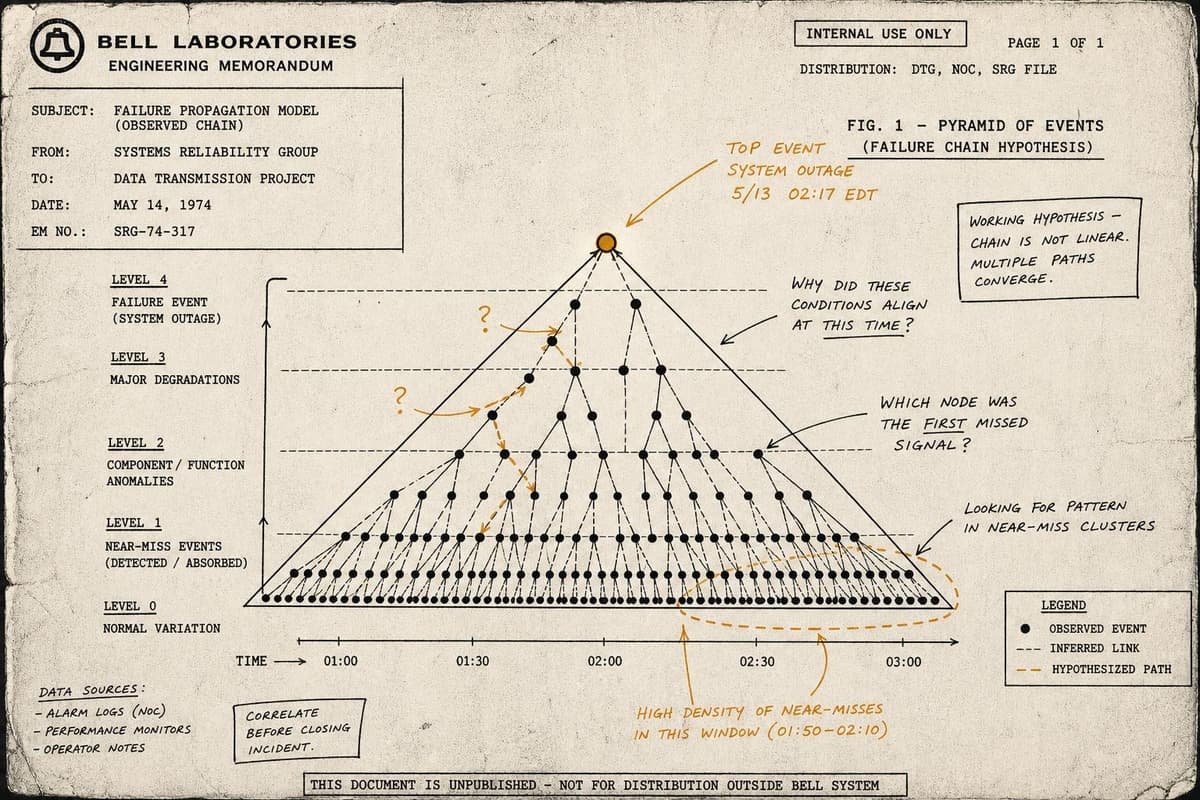
Nobody budgets for the cost of almost-incidents. The production system that degraded for eleven minutes and then recovered on its own. The deployment that caused elevated error rat…
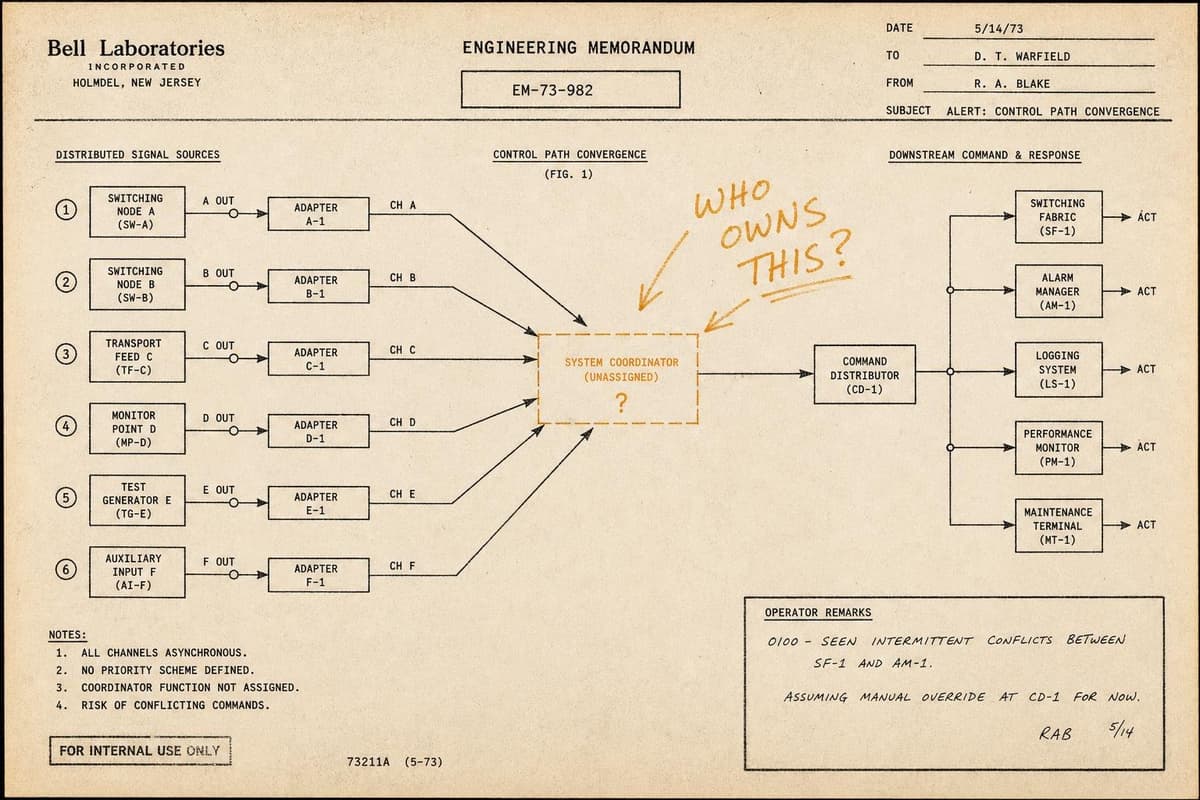
The failure mode nobody writes about in their postmortem isn't the database that crashed or the deploy that went sideways. It's the service three hops away that nobody on your team…
The incident is over. The service is green. Someone writes "resolved" in the Slack thread and closes the bridge. The on-call engineer who fought through the night hands off to the…
You're in the postmortem. The timeline is on the screen. Someone walks through the sequence: the deploy went out, the error rate climbed, the alert fired, the on-call responded, th…
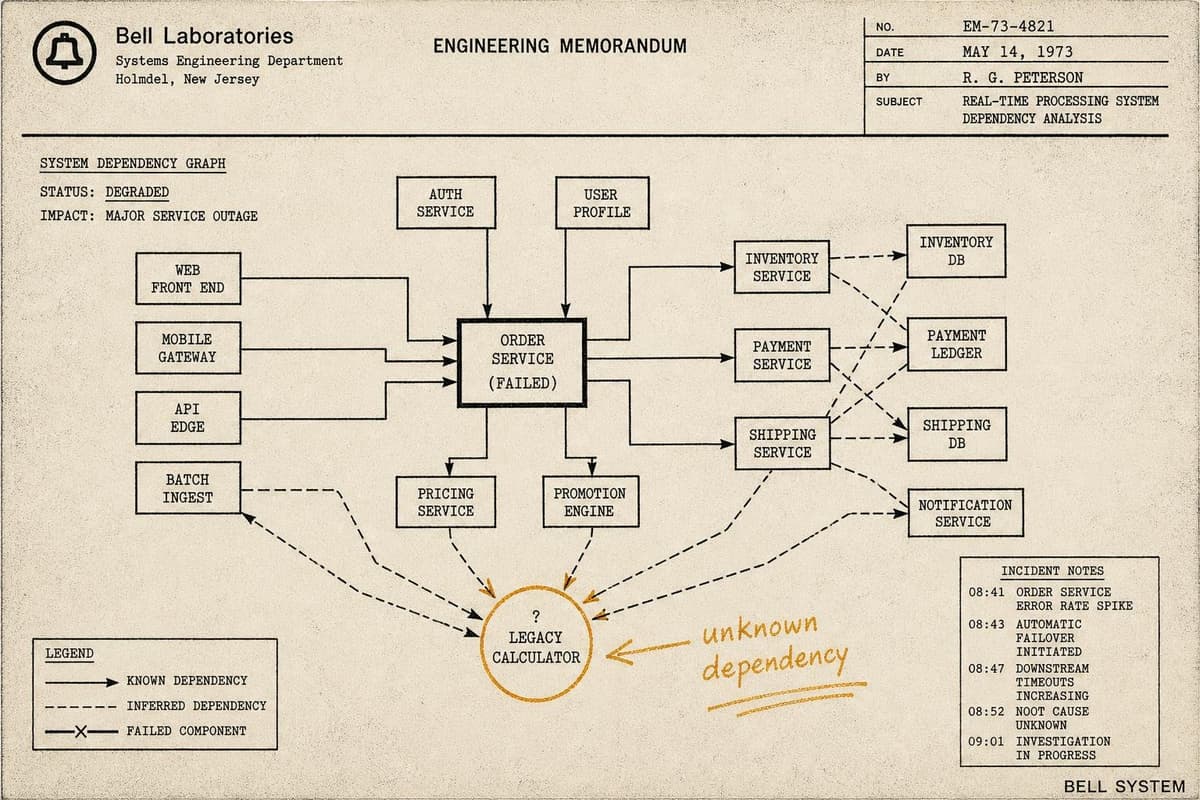
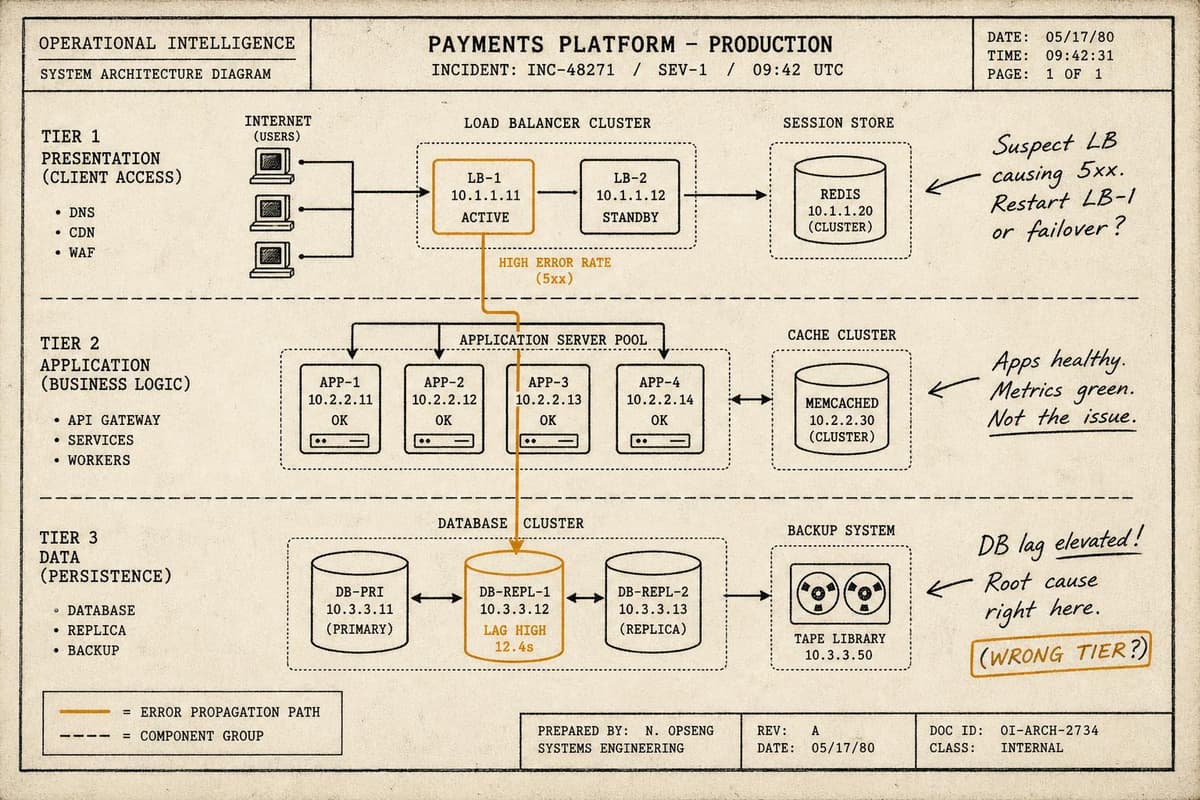
The call comes in at 2:47am. Database latency is spiking. You page the on-call DBA, scope the incident to the database tier, and start working the problem. Forty minutes later, you…
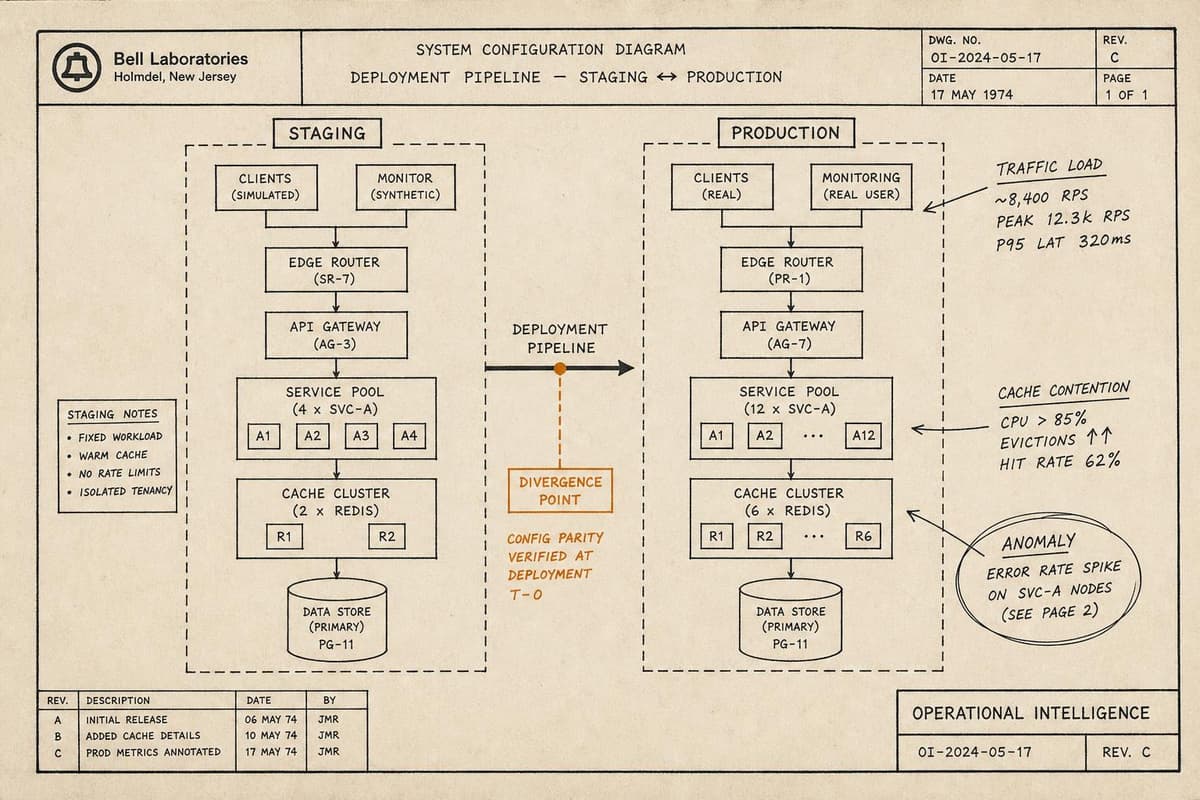
You've seen this movie. The change passes every test. Staging looks clean. The deploy goes out on a Tuesday afternoon — low traffic, good timing, cautious team. Then something star…
The postmortem is done. The action items are filed. Someone updated the runbook. You closed the ticket, and the on-call rotation moved on. Three months later, a different system fa…
Three hundred alerts in a week. Forty of them actionable. The other two hundred and sixty? Your team learned to ignore those months ago — they just haven't gotten around to deletin…
Most teams treat oncall as a staffing problem. Someone has to be paged; someone has to respond. The rotation exists to distribute that burden. Fair enough. But if that's the whole…
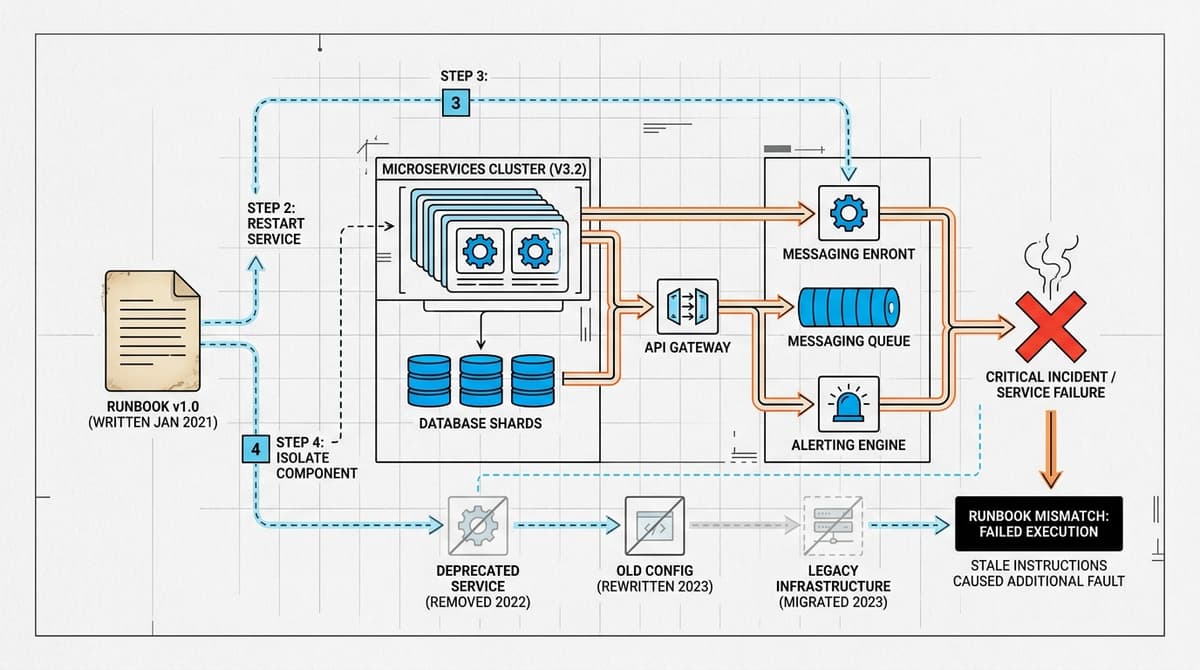
You're twenty minutes into an incident. The alerts are firing, the on-call channel is filling up, and someone pastes a link to the runbook. You follow step three. Nothing changes.…
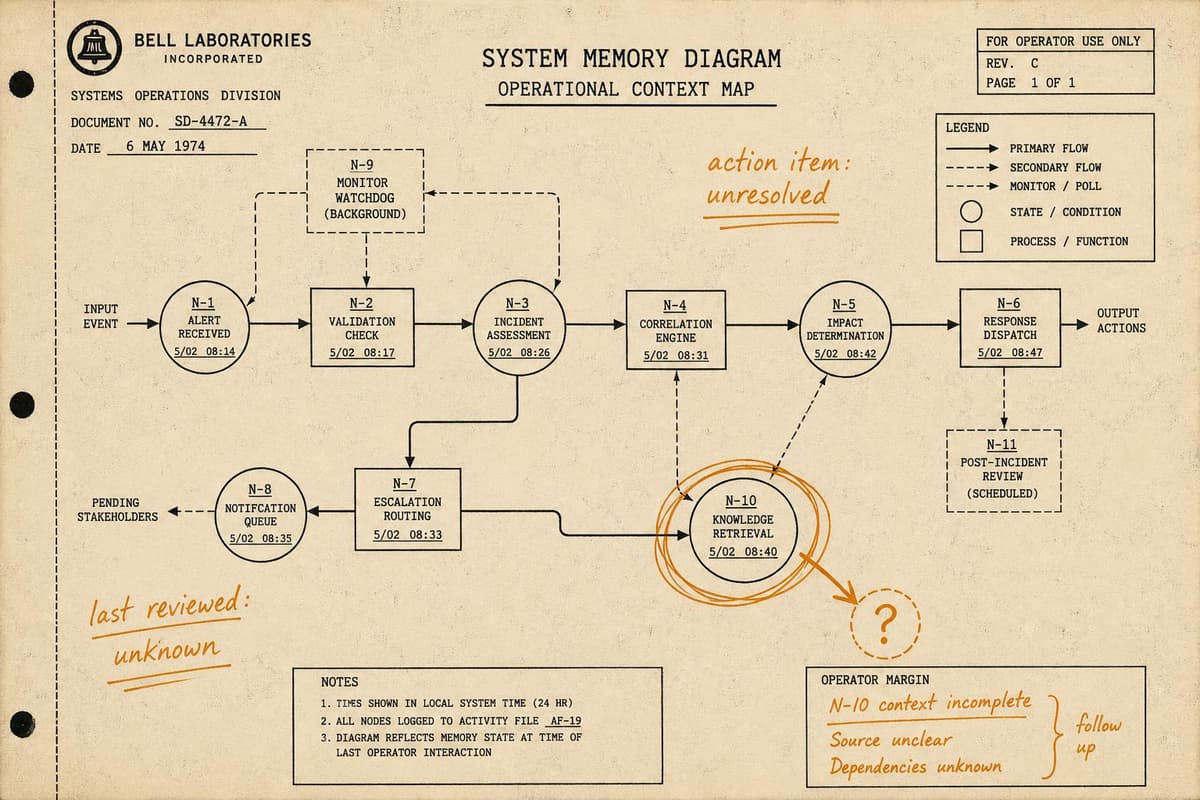
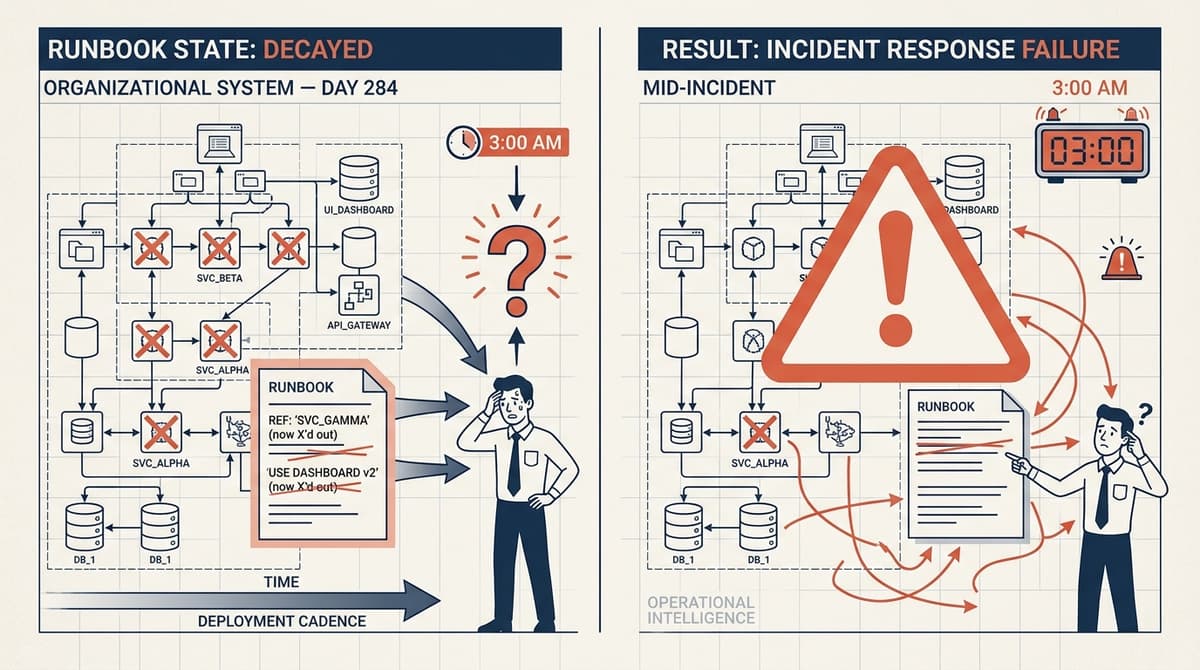
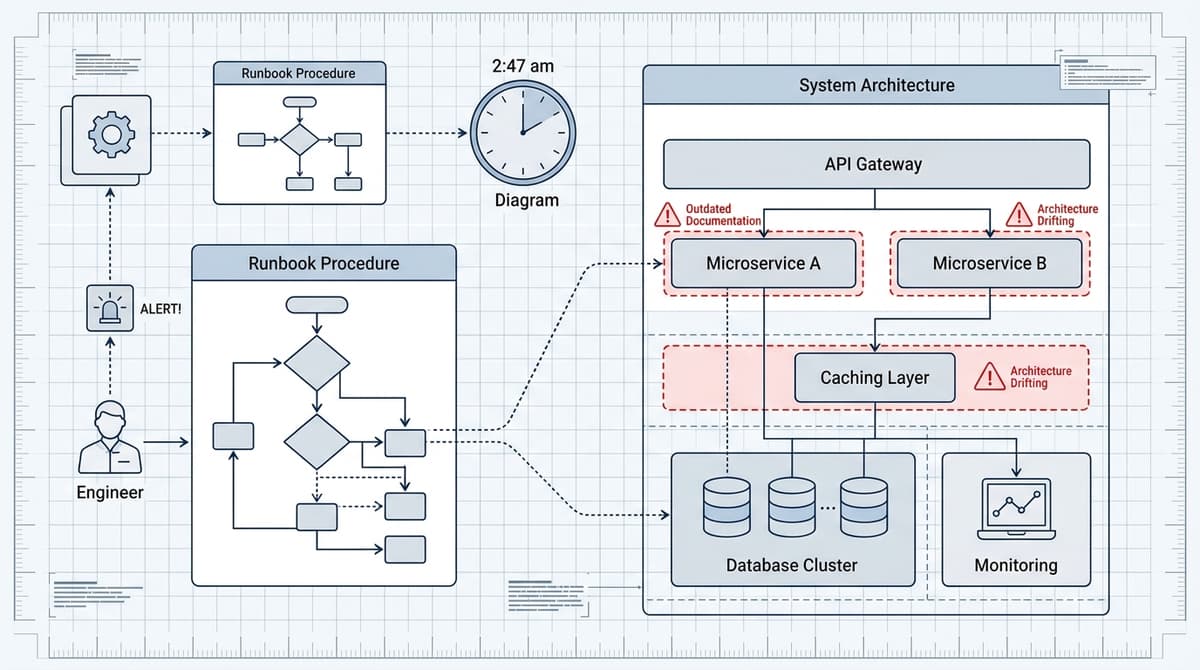
There's a particular kind of dread that hits when you're mid-incident, you've pulled up the runbook, and the first step references a service that was deprecated eight months ago. T…
It's 2:47am. The alert fires. You find the runbook, follow it step by step, and the system gets worse. Somewhere between the last incident and this one, the architecture changed —…
There's a version of this newsletter that opens with a crisp thesis, three supporting data points, and a clean close. That version would be dishonest right now. Because the most op…