


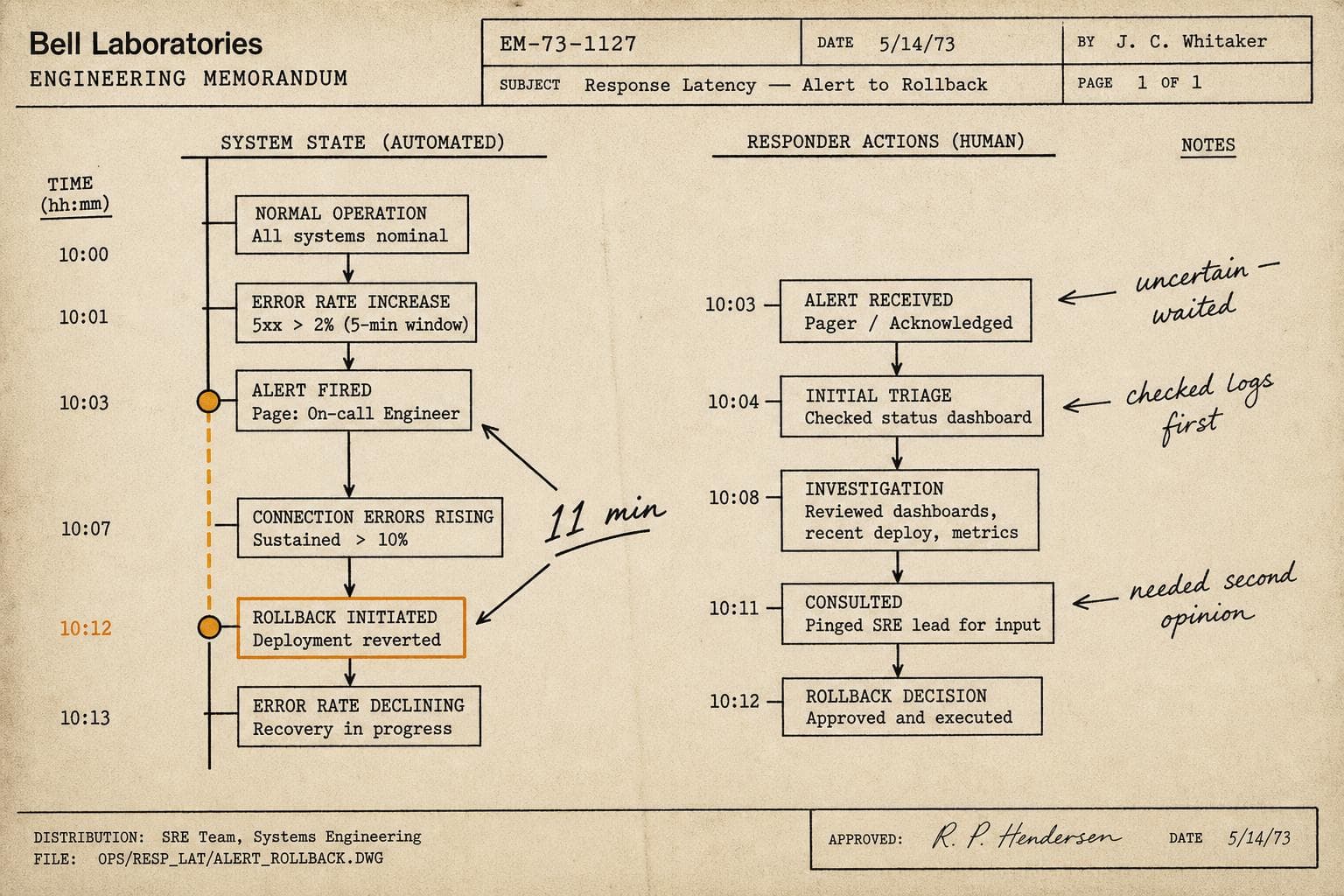
You're in the postmortem. The timeline is on the screen. Someone walks through the sequence: the deploy went out, the error rate climbed, the alert fired, the on-call responded, the rollback happened. Forty-five minutes of production impact, documented cleanly. Action items assigned. Meeting adjourned.
And somewhere in that room, the question nobody asked: why did the on-call take eleven minutes to start the rollback after the alert fired?
Not as blame. As signal.
The Timeline Is the Easy Part
Most postmortems are good at reconstructing what happened to the system. They're much worse at reconstructing what happened to the people responding to it. The technical sequence is recoverable from logs. The human sequence — what the responder saw, what they tried first, what they weren't sure about, where they got stuck — lives mostly in memory, and memory degrades fast under post-incident relief.
This matters because the failure modes that will actually hurt you aren't usually in the code. They're in the gap between "alert fired" and "correct action taken." That gap is where your runbooks, your tooling, your team's shared mental models, and your escalation paths all get stress-tested simultaneously. And most postmortems treat it as a footnote.
The technical root cause gets a section. The human factors get an action item: "improve runbook clarity." Which is the operational equivalent of writing "be better" and calling it a plan.
What the Response Sequence Actually Reveals
When you slow down and reconstruct the responder's experience — not just the system's behavior — you start finding a different class of problem.
The eleven-minute delay before rollback might reveal that the on-call wasn't sure the rollback was safe. Which reveals that the deploy process doesn't make rollback safety obvious. Which reveals a gap in how deploys are communicated to the team. That's three distinct problems, none of which show up in a timeline that only tracks system state.
Or the delay reveals that the responder was waiting for a second opinion before acting. Which might be exactly the right instinct given your blast radius — or it might be a symptom of an on-call rotation where people don't feel empowered to act alone. Those are very different problems with very different fixes.
The pattern I keep seeing: teams optimize their postmortems for the story they can tell confidently, which is the technical story. The human story requires asking responders questions that feel uncomfortably close to "why didn't you do the right thing faster" — and most postmortem facilitators don't want to go there. So they don't. And the same response delays show up in the next incident.
Running the Human Timeline
The fix isn't complicated, but it requires deliberate structure. After you've built the technical timeline, build a parallel responder timeline. For each decision point — first action taken, escalation triggered, rollback initiated, customer communication sent — ask the responder: what did you know at that moment, what were you uncertain about, and what would have helped you act faster or more confidently?
This isn't a blame exercise. Frame it explicitly as a systems question: what does your uncertainty at that moment tell us about our tooling, documentation, or team norms? The responder's hesitation is data about the system they were operating in, not a character flaw.
A few questions that tend to surface useful signal:
- At what point did you know what the right action was? What made it clear?
- Was there a moment where you weren't sure whether to escalate? What resolved that?
- What information were you looking for that you couldn't find quickly?
- If this happened again tomorrow, what would make you faster?
The answers to these questions are your actual action items. Not "improve runbook clarity" — "add a rollback safety checklist to the deploy runbook because the responder didn't know whether the migration had run." Specific, testable, owned.
The Postmortem as a Learning System
I've written before about how your on-call rotation is a diagnostic tool most teams aren't reading. The postmortem is the same kind of instrument — but only if you're measuring the right things. A postmortem that reconstructs the technical failure and ignores the response experience is like a postmortem that documents the fire but not the broken smoke detector.
The goal isn't to make responders feel good about their performance. It's to understand what your system — including the humans in it — actually did under pressure, so you can make it more reliable next time. That requires asking the harder question: not just what broke, but what made it hard to fix.
The teams that get better at incidents aren't the ones with the cleanest timelines. They're the ones who are honest about the eleven minutes.