


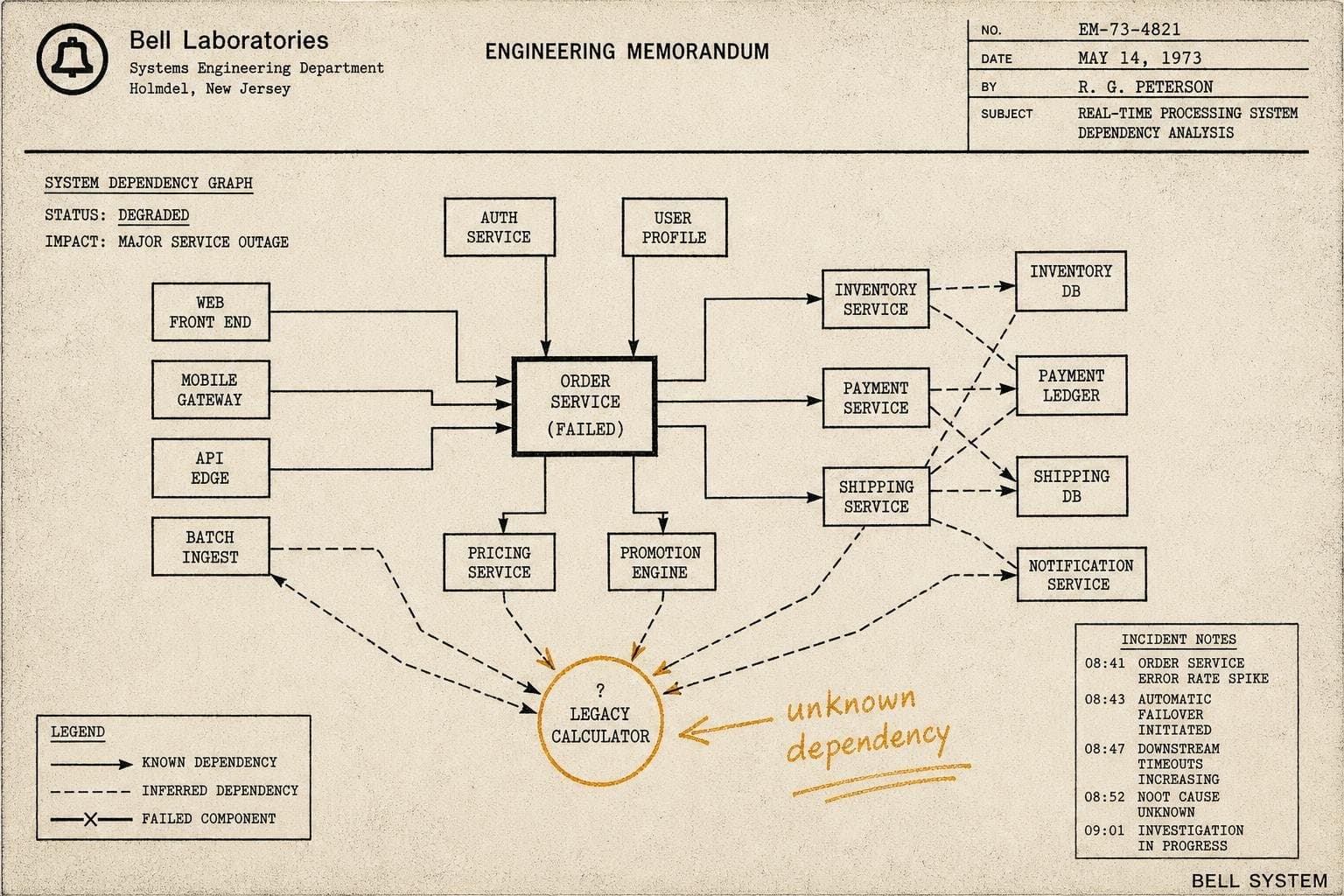
The failure mode nobody writes about in their postmortem isn't the database that crashed or the deploy that went sideways. It's the service three hops away that nobody on your team knew existed — the one that quietly handled a thing your system assumed would always work, until it didn't.
Hidden dependencies are the dark matter of production systems. They don't show up in your architecture diagrams. They don't appear in your runbooks. They're not in the oncall rotation because nobody thought to add them. And when they fail, your incident response starts with twenty minutes of "why is this broken?" before anyone even begins asking the right questions.
The Dependency Graph You Have Versus the One You Actually Need
Most teams have some version of a service map. It lives in Confluence, or in a diagram someone made during a planning session, or in the collective memory of the two engineers who've been around longest. It shows the obvious connections — your API calls your database, your workers pull from your queue, your frontend hits your CDN.
What it doesn't show: the internal DNS resolver that three services silently depend on. The shared secrets manager that gets called on every cold start. The logging pipeline that, when it backs up, causes your application to block on writes because someone set the wrong timeout. The third-party geocoding API that your address validation service calls, which your checkout flow calls, which your payment service calls — and which has a rate limit nobody documented.
These aren't exotic failure scenarios. They're the normal texture of systems that have been running and growing for a few years. Every dependency that gets added makes sense at the time. The accumulation is what becomes dangerous.
The gap between the dependency graph you think you have and the one that actually exists in production is a direct measure of your incident response overhead. When something breaks and your mental model is wrong, every diagnostic step costs double — you're debugging the system and updating your understanding of the system simultaneously, under pressure, while someone is paging you for a status update.
What Actually Reveals Hidden Dependencies (It's Not What You Think)
The standard advice is to invest in distributed tracing. That's correct, and if you're not doing it, start. But tracing only shows you the dependencies that are exercised in your current traffic patterns. The dependency that only activates during a specific code path — say, the one that fires when a user resets their password and triggers an account audit — won't appear in your traces until that path runs.
The more reliable discovery mechanism is controlled failure. Not chaos engineering in the conference-talk sense, but the boring, systematic version: take a service down in a non-production environment and watch what complains. Not just what throws errors — what slows down. What starts timing out in unexpected places. What triggers alerts in systems you didn't think were connected.
The second mechanism is incident archaeology. Go back through your last six months of postmortems and look specifically for the moment in each timeline where the team said "we didn't know that X depended on Y." That's not just a lesson learned — it's a data point about where your dependency graph is wrong. Cluster those moments and you'll find the parts of your system where the mental model has drifted furthest from reality.
The Organizational Problem Underneath the Technical One
Here's the part that doesn't fit neatly into a runbook: hidden dependencies are usually a symptom of how teams communicate, not just how systems are built.
When a team adds a dependency on a shared service, they often don't tell the team that owns that service. When a platform team makes a change to an internal library, they often don't know which downstream services will be affected. When an engineer leaves, the knowledge of why a particular integration exists — and what it's sensitive to — leaves with them.
The technical fix is better observability and dependency tracking. The organizational fix is making dependency changes a first-class communication event. Not a bureaucratic approval process, but a lightweight norm: if you're adding a dependency on something you don't own, tell the people who own it. If you're changing something that others depend on, find out who they are before you ship.
This sounds obvious. It almost never happens consistently, because it requires friction in the moment to prevent pain later, and humans are bad at that trade-off under delivery pressure.
What to Do This Week
Pull up your last three postmortems. For each one, ask: were there any dependencies involved that surprised the team? If yes, are those dependencies now documented somewhere that would actually be consulted during an incident?
If the answer to the second question is "probably not," you have a concrete thing to fix that will make your next incident faster to resolve. Not a process overhaul — just a runbook entry, a service catalog update, a Slack message to the team that owns the thing you depend on.
The dependency you document today is the one that won't cost you an hour of confusion at 3am.