


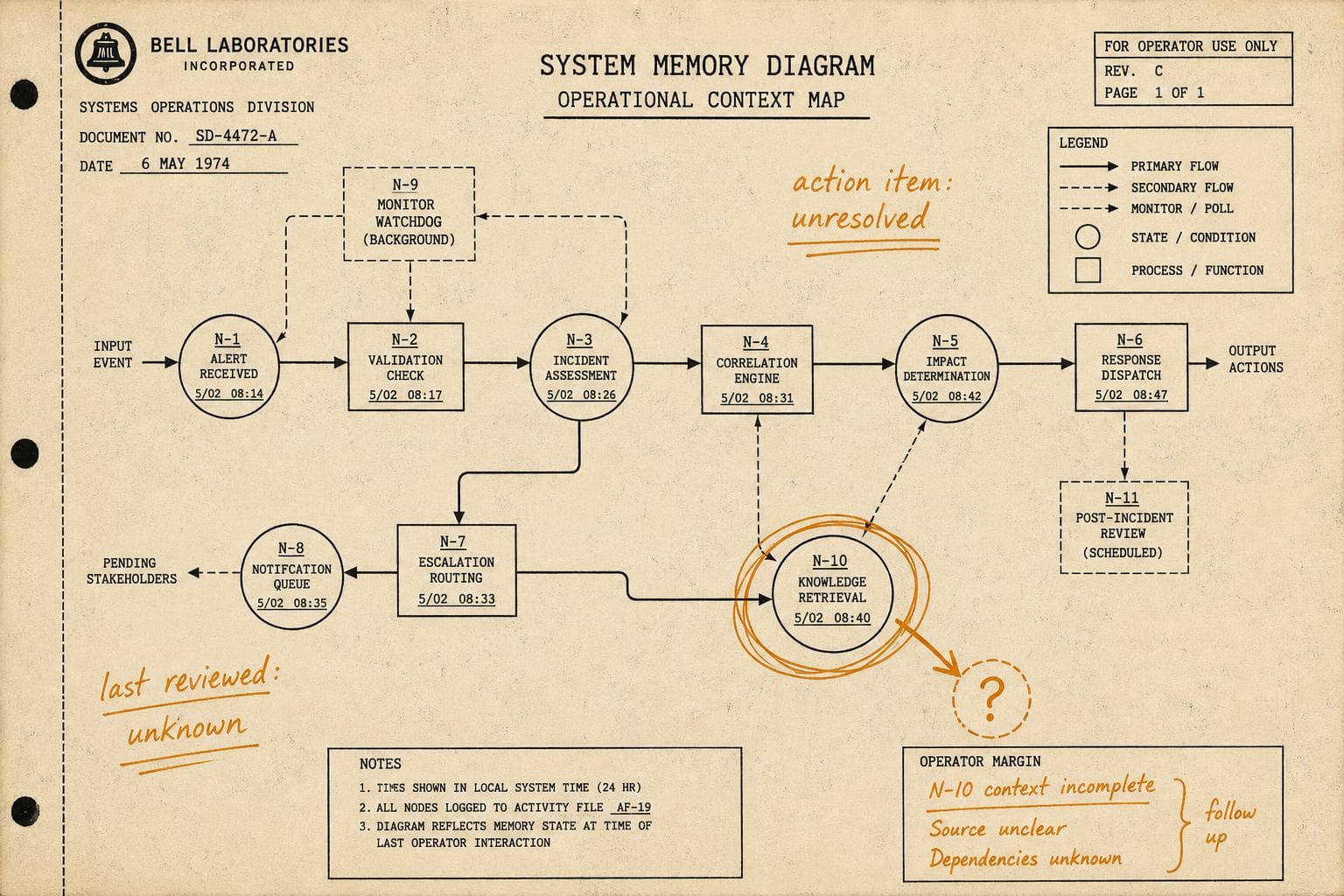
The postmortem is done. The action items are filed. Someone updated the runbook. You closed the ticket, and the on-call rotation moved on.
Three months later, a different system fails in a way that rhymes with the last one — same class of problem, different component, different team. Nobody connected the dots because the dots were in different Jira projects, different Slack channels, different people's memory.
This is the pattern that actually kills operational maturity: not the incidents themselves, but the organizational forgetting that happens between them.
Incident Memory Is a Perishable Resource
Most teams treat postmortems as closure. You write the document, you assign the follow-ups, you move on. The implicit assumption is that the learning happened — that the people in the room absorbed it, and the system is now safer.
But postmortems are point-in-time artifacts. The engineer who ran the incident review gets promoted or leaves. The action items get deprioritized when the next quarter's roadmap lands. The runbook update gets made, but nobody reads runbooks until they're already mid-incident. The institutional knowledge that felt solid in the postmortem meeting has a half-life measured in weeks.
I'd argue the real failure mode isn't writing bad postmortems. It's writing good ones and then letting them decay in a wiki nobody searches under pressure.
The Gap Between Writing and Retrieval
There's a specific operational trap here that doesn't get enough attention: the difference between recording a lesson and retrieving it at the moment it matters.
Teams invest heavily in the recording side. Incident trackers, postmortem templates, blameless culture, five-whys analysis — all of that is genuinely valuable. But retrieval is almost entirely ad hoc. When something starts going wrong at 2am, the on-call engineer searches Slack, maybe checks a runbook, maybe remembers a conversation from six months ago. The postmortem that would have told them exactly what to do is sitting in a Confluence page with a title that doesn't match the symptoms they're seeing.
The pattern suggests that operational memory needs to be embedded in the places engineers actually look during incidents — not stored in a separate system they have to remember to consult. Alert annotations that link to relevant postmortems. Runbook sections that explicitly reference prior incidents with similar signatures. Dashboard panels with "last time this metric looked like this, here's what happened" notes.
Boring to build. Genuinely useful at 2am.
What Teams That Learn Actually Do Differently
The teams that compound operational knowledge over time share a few habits that aren't about tooling.
They treat the postmortem as the start of a conversation, not the end of one. The document gets reviewed at the next team meeting. New engineers read old postmortems as onboarding material. Someone owns the action items with actual accountability, not just assignment.
They also maintain a lightweight incident taxonomy — not a formal classification system, but a shared vocabulary for failure modes. "This is a thundering herd problem" or "this looks like our Q3 database failover issue" gives teams a way to pattern-match across incidents without having to reconstruct the full history from scratch.
And they're honest about which action items actually got done. The postmortem that says "add circuit breaker to payment service" and the ticket that's been sitting in the backlog for eight months are a liability, not a safety net. False confidence in unfixed problems is worse than acknowledged risk.
Three Things Worth Doing This Week
If your team's incident knowledge is living primarily in documents nobody reads under pressure, a few targeted interventions move the needle:
Annotate your alerts. Add links to the two or three most relevant postmortems directly in your alerting configuration. When that alert fires again, the context is one click away, not a Confluence search.
Run a postmortem retrospective. Pick five incidents from the last year and ask: did the action items actually ship? If not, why not? The answer usually reveals something real about your team's capacity or prioritization, not just follow-through.
Make failure modes part of onboarding. New engineers should read your three most instructive postmortems before they're on call. Not as a formality — as actual preparation for the systems they're about to own.
The incident you survived taught you something. The question is whether that knowledge survives long enough to matter the next time.