


The incident is over. The service is green. Someone writes "resolved" in the Slack thread and closes the bridge. The on-call engineer who fought through the night hands off to the morning shift with a Slack message that reads something like: "Had some issues with the payment service, looks stable now, keep an eye on it."
That handoff is where the next incident begins.
Most teams spend real energy on the acute phase of incident response — the detection, the escalation, the fix. The handoff gets whatever's left, which is usually nothing. And so the engineer who inherits the watch starts their shift with a system that is technically "stable" but carrying unresolved state: a workaround that hasn't been documented, a mitigation that will expire when traffic spikes, a root cause that's been hypothesized but not confirmed. They don't know what they don't know. When something goes sideways three hours later, they're starting from scratch.
The Handoff Is a Knowledge Transfer Problem, Not a Logistics Problem
Teams tend to treat handoffs as scheduling — who's on, who's off, when the transition happens. The actual problem is epistemic: how does the incoming engineer acquire the situational awareness that the outgoing engineer built over the last several hours?
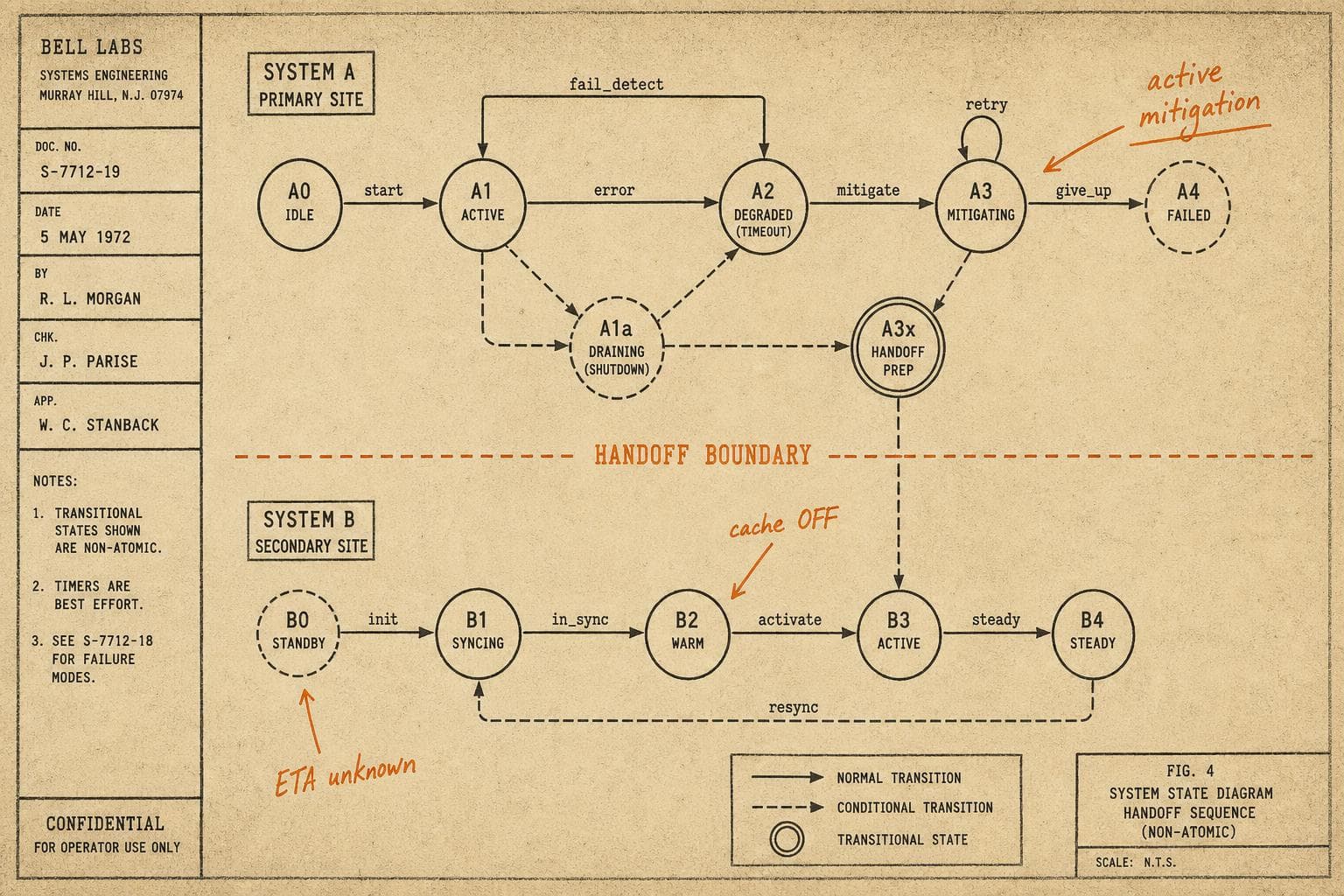
That awareness isn't just "what broke." It includes the current theory of why it broke, what was tried and ruled out, what's been temporarily patched versus actually fixed, what signals to watch, and — critically — what the system looked like before the incident so you can recognize if it's drifting back toward the same failure mode.
None of that fits in a Slack message. Most of it doesn't even fit in a ticket comment, because it's the kind of knowledge that feels obvious to the person who has it and invisible to the person who doesn't.
The operational pattern that actually works here is treating the handoff as a mini-postmortem in real time. Not a full blameless retrospective — just a structured five-minute transfer that covers: current system state, what's confirmed versus suspected, what mitigations are active and when they expire, and what the incoming engineer should escalate immediately versus monitor. The format matters less than the discipline. Teams that do this consistently tend to catch the second incident before it becomes a second incident.
Degraded State Is the Hardest Thing to Communicate
There's a specific failure mode worth naming: the system that is technically operational but running in a degraded mode that nobody has formally acknowledged.
A cache that's been disabled as a workaround. A circuit breaker that's been manually opened. A rate limit that's been temporarily raised to absorb traffic during the incident. These are all states that look fine in a dashboard unless you know to look for them — and the incoming engineer doesn't know to look for them unless someone told them.
This is where runbooks and incident documentation earn their keep, and also where they most commonly fail. I wrote last month about runbooks that lie to you; the degraded-state problem is the inverse: the runbook that's accurate but silent about the current exception. The system isn't running the way the runbook describes, and nobody updated the runbook, and now the incoming engineer is making decisions based on a model of the system that stopped being true six hours ago.
The fix is unglamorous: before you hand off, write down every active deviation from normal operating state. Not in prose — a list, with expected resolution times where you have them. If you don't have a resolution time, say so explicitly. "Cache disabled, no ETA" is more useful than silence.
What Good Looks Like Under Pressure
The teams that handle this well share a few patterns. They treat the handoff as a first-class artifact of incident response, not an afterthought. They have a template — not a rigid form, but a shared vocabulary for what "current state" means. And they've normalized the idea that "I don't know" is a valid and important thing to write in a handoff note.
That last one is harder than it sounds. There's social pressure to hand off a clean story, to present the incident as resolved and understood even when it isn't. The engineer who writes "root cause unknown, treating as stable but not confident" is doing their team a service. They're also doing something that feels uncomfortable: admitting uncertainty at the moment of transition.
The alternative is an incoming engineer who inherits false confidence, makes decisions based on it, and pages the whole team at 2am when the thing that was "probably fine" turns out not to be.
The handoff isn't the end of the incident. It's the moment where the incident either gets properly closed or quietly continues under new management. Treat it accordingly.
Operational note: If your team doesn't have a handoff template, the fastest way to build one is to look at your last three incidents and ask: what did the incoming engineer not know that they should have? The answers will write the template for you.