


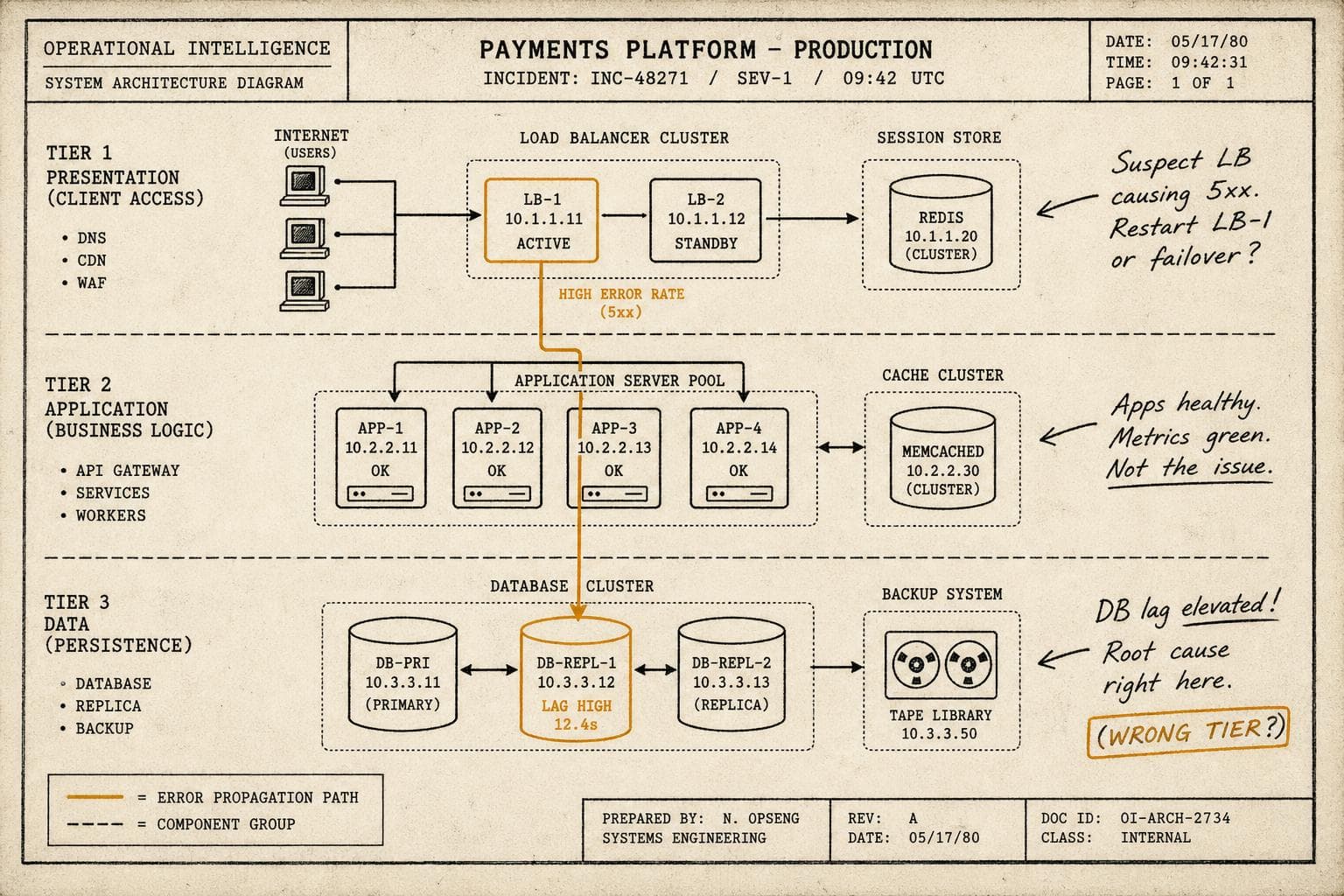
The call comes in at 2:47am. Database latency is spiking. You page the on-call DBA, scope the incident to the database tier, and start working the problem. Forty minutes later, you discover the actual issue: a misconfigured load balancer rule that was silently dropping connections to a subset of application servers, which were then hammering the database with retries. The database was a symptom. You spent forty minutes treating the wrong patient.
This is the blast radius problem. Not the one vendors talk about — the "limit the impact of a bad deploy" version — but the diagnostic version: the gap between where you think an incident lives and where it actually lives. Most teams get this wrong in the same direction, every time.
Incidents Don't Respect Your Service Boundaries
The way most teams organize their monitoring and on-call rotations reflects their org chart, not their system's actual failure topology. Database team owns database alerts. Networking team owns networking alerts. Application team owns application alerts. Clean lines of ownership, terrible incident response.
Production systems fail at the seams. The interesting failures — the ones that page you at 3am and resist diagnosis — are almost always cross-boundary. A memory leak in one service changes the behavior of another. A CDN misconfiguration surfaces as application errors. A certificate rotation in one dependency cascades into authentication failures three hops away.
The blast radius of an incident isn't defined by which team's service is misbehaving. It's defined by the failure's propagation path through your system. And that path rarely follows the org chart.
The practical consequence: when you scope an incident, your first instinct about ownership is probably right about 60% of the time. The other 40% is where you lose hours.
The Scope Anchoring Trap
There's a cognitive pattern that makes this worse. The moment you name an incident — "database incident," "payment service degradation," "CDN issue" — you've anchored the team's mental model. Subsequent evidence gets filtered through that frame. Symptoms that don't fit get explained away rather than treated as signals that the scope is wrong.
I'd argue this is one of the most expensive failure modes in incident response, and it's almost never discussed in postmortems because the postmortem is written after you've found the real cause. The narrative gets reconstructed to look like a linear investigation. The forty minutes you spent confidently debugging the wrong thing gets compressed into a sentence.
The fix isn't complicated, but it requires discipline under pressure: treat your initial scope as a hypothesis, not a conclusion. Build explicit scope-revision checkpoints into your incident process. After the first thirty minutes, ask: what evidence would tell us this is actually a different problem? If you can't answer that question, you're not investigating — you're confirming.
What Good Scope Management Looks Like
A few patterns that actually help:
Start with symptoms, not systems. "Users can't complete checkout" is a better incident frame than "payment service is down." The symptom frame keeps the scope open; the system frame closes it prematurely.
Map the propagation path early. Before you're deep in debugging, spend five minutes asking: if this failure is actually upstream of where we're looking, what would we expect to see? Then check. This costs five minutes and occasionally saves four hours.
Designate a scope skeptic. In a major incident, someone should have the explicit job of questioning the current scope. Not the incident commander — they're managing the response. A separate role whose only job is to ask "are we sure this is the right problem?" every thirty minutes.
Watch for retry storms. Retries are the most common mechanism by which a localized failure becomes a blast radius problem. If you're seeing unexpected load on a downstream service, assume retries before you assume a new failure.
Noteworthy Pattern: The Postmortem That Skips the Diagnosis
The most common gap I see in postmortems isn't the root cause analysis — teams have gotten reasonably good at that. It's the diagnosis timeline. Most postmortems document what the problem was and how it was fixed. Few document the wrong turns: the hypotheses that were tested and rejected, the scope that was revised, the forty minutes spent on the database when the problem was the load balancer.
That diagnostic history is where the operational learning lives. If your postmortem template doesn't have a section for "what did we investigate that turned out to be wrong, and why did we investigate it," you're leaving the most useful part of the incident on the floor.
Add it. It's uncomfortable to write, which is exactly why it's valuable.
The blast radius problem doesn't go away as systems mature — it usually gets worse, because mature systems have more dependencies and more subtle failure modes. The teams that handle it well aren't the ones with the best monitoring. They're the ones who've learned to hold their initial diagnosis loosely, and who've built the habit of asking "what if we're wrong about where this lives?" before they're forty minutes deep in the wrong rabbit hole.