


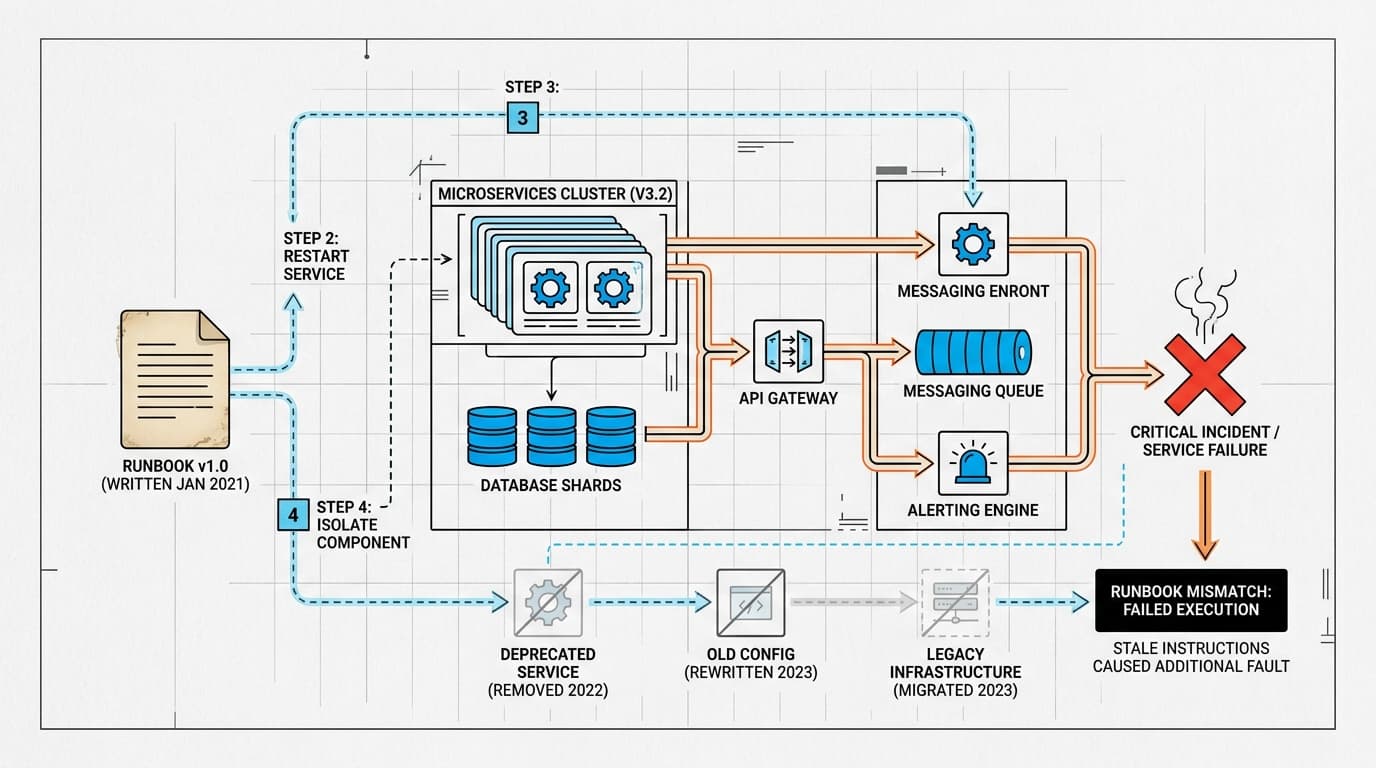
You're twenty minutes into an incident. The alerts are firing, the on-call channel is filling up, and someone pastes a link to the runbook. You follow step three. Nothing changes. You follow step four. The service gets worse. By step seven, you realize the runbook was written for a version of the system that no longer exists.
This happens constantly. And the cruel irony is that a team with no runbook at least knows they're improvising. A team with a stale runbook thinks they have a plan.
Runbooks Rot the Moment You Stop Touching the System
The problem isn't that engineers write bad runbooks. Most runbooks are accurate when they're written. The problem is that production systems change continuously — deployments, dependency upgrades, configuration drift, infrastructure migrations — and documentation doesn't change with them. The runbook stays pinned to a moment in time while the system keeps moving.
I'd argue this is one of the most underappreciated failure modes in incident management. Teams invest real effort in writing runbooks after postmortems, feel good about the artifact, and then never build any mechanism to keep it current. The runbook becomes organizational debt disguised as organizational knowledge.
The failure mode is particularly bad because it's invisible until you're already in an incident. A broken deployment pipeline fails loudly. A stale runbook fails quietly — it just costs you thirty minutes of confused troubleshooting before someone with enough context says "wait, that's not how it works anymore."
The Practices That Actually Keep Runbooks Honest
There are a few patterns that work, and they share a common trait: they force the runbook to be exercised, not just stored.
Runbook-driven chaos testing. If your chaos experiments require you to follow the runbook to recover, you'll find out fast whether the runbook is accurate. This isn't just about testing the system's resilience — it's about testing the documentation's resilience. Teams that run regular game days or failure injection exercises tend to have dramatically better runbooks, not because they're more disciplined writers, but because they get immediate feedback when the instructions are wrong.
Linking runbooks to deployment gates. Some teams have started treating runbook review as part of the deployment process for services with significant operational complexity. If you're changing the behavior of a critical service, you're also responsible for updating the runbook that describes how to respond when that service misbehaves. This doesn't scale to every change, but for high-stakes services it creates the right forcing function.
Expiration dates as a cultural signal. A runbook with a "last verified" date that's eighteen months old is a runbook you shouldn't trust. Some teams add explicit expiration metadata to runbook sections — not as a bureaucratic requirement, but as a signal to the on-call engineer that they should verify before they execute. The goal isn't to block action during an incident; it's to calibrate confidence appropriately.
None of these are revolutionary. What they have in common is treating runbooks as living operational artifacts rather than completed documents.
The Organizational Pattern Underneath
The deeper issue is that runbook quality is a proxy for how a team thinks about operational knowledge transfer. Teams that treat runbooks as one-time postmortem outputs will always have stale runbooks. Teams that treat them as part of the operational loop — something that gets exercised, tested, and updated as the system evolves — tend to have runbooks that actually help during incidents.
The signal I look for in engineering organizations isn't whether they have runbooks. Almost everyone has runbooks. The signal is whether the on-call engineers trust them. If the answer is "mostly, but you should verify the newer sections" or "check with whoever owns that service first," the runbooks are decorative. They exist to make the team feel prepared rather than to actually prepare them.
That gap between feeling prepared and being prepared is where incidents get expensive.
One thing to watch: If your team is doing a postmortem in the next few weeks, add one question to the review: Did the runbook help, hurt, or get ignored? The answer will tell you more about your operational documentation health than any audit.