


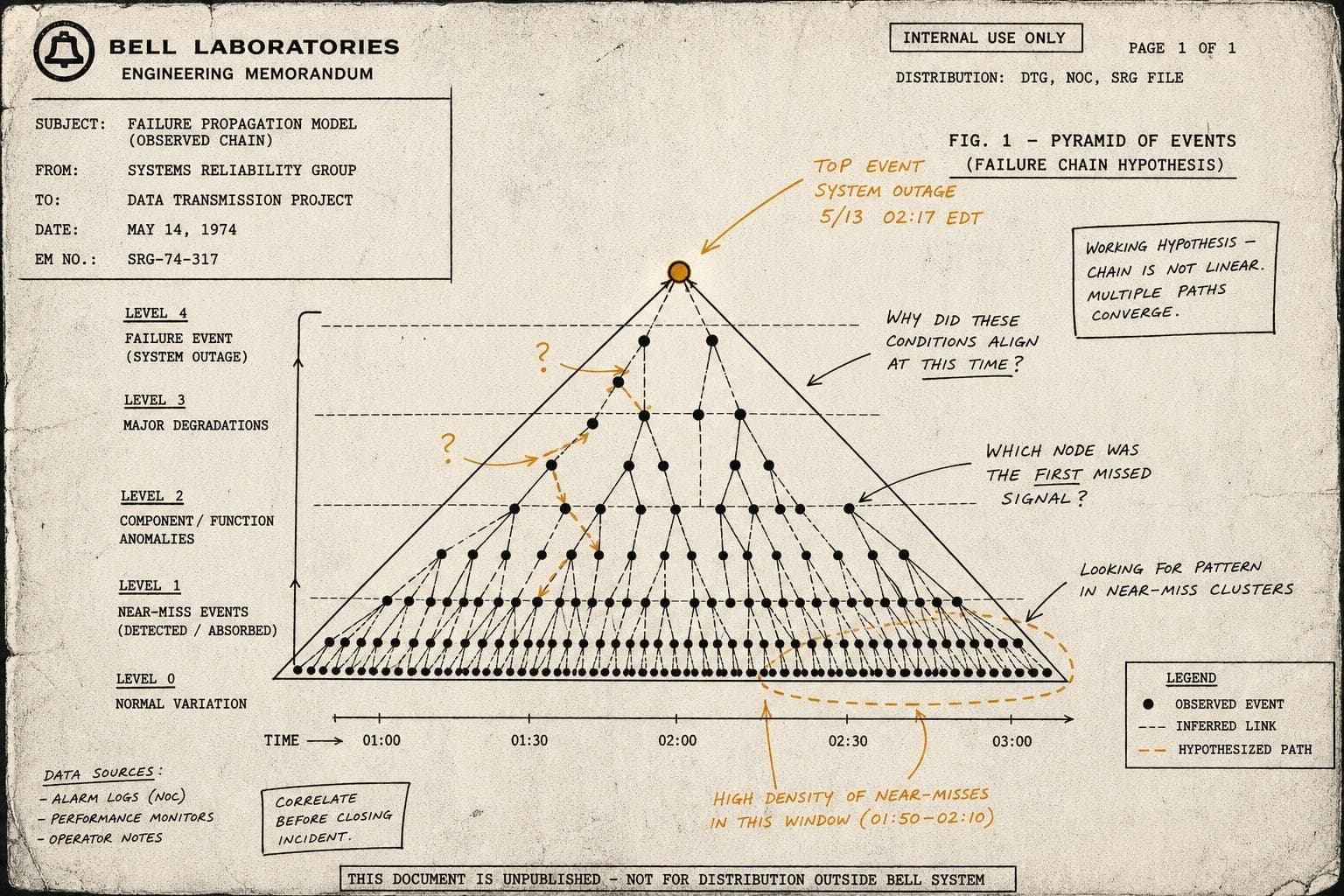
Nobody budgets for the cost of almost-incidents.
The production system that degraded for eleven minutes and then recovered on its own. The deployment that caused elevated error rates in a single region before traffic shifted away naturally. The database failover that completed successfully but took forty seconds longer than the runbook said it should. These events don't make it into postmortems. They don't generate action items. They don't get tracked anywhere. And they are, collectively, the most accurate predictor of what's going to break you at 2am on a Saturday.
This is reliability debt — not the technical kind that lives in your backlog, but the operational kind that accumulates in the gap between "it worked out" and "we understood why."
Near-Misses Are Data You're Throwing Away
Every team I've seen run production systems develops an informal taxonomy of incidents: the real ones that get postmortems, and the near-misses that get a Slack message and a relieved emoji. The problem is that near-misses are statistically more valuable than actual incidents, because they're more frequent and they're telling you something your monitoring isn't.
The logic of reliability engineering — borrowed from aviation and nuclear safety — is that major failures are almost never singular events. They're the visible tip of a much larger pyramid of smaller failures, degradations, and anomalies that went unexamined. When a system fails catastrophically, the postmortem almost always uncovers a trail of warning signs that were present for weeks or months. Someone noticed the database connection pool was running hot. Someone saw the memory leak in the logs. Someone mentioned in standup that the third-party API had been flaky. None of it got written down in a way that connected the dots.
The teams that are actually good at reliability — not the ones with the best SLO dashboards, but the ones who sleep through the night — have built a habit of treating near-misses as first-class operational events. Not with the full postmortem ceremony, but with enough structure to capture: what happened, what could have made it worse, and what we'd need to see to catch it earlier next time.
The Ceremony Trap
Here's where most teams go wrong when they try to fix this: they add process. They create a near-miss template. They add a standing agenda item to the weekly engineering meeting. They build a Jira ticket type. And then, six weeks later, nobody is filling out the template because it takes twenty minutes and the incident resolved itself and there's a real sprint to get through.
The ceremony trap is real. The goal isn't to create a parallel postmortem process for every blip — it's to lower the activation energy for capturing signal. The best implementations I've seen are almost embarrassingly simple: a single Slack channel where anyone can drop a two-sentence note about something that felt off, with a lightweight weekly review where someone with operational context reads through and flags anything worth a closer look.
The key insight is that you're not trying to analyze every near-miss in real time. You're trying to preserve the signal long enough for patterns to emerge. A single degraded deployment is noise. Four degraded deployments in the same service over six weeks is a pattern that tells you something about your deployment process, your test coverage, or your infrastructure dependencies.
What You're Actually Measuring
The deeper problem with ignoring near-misses is what it does to your team's mental model of the system. When the only events that get examined are the ones that caused customer impact, you develop a distorted picture of where your actual risk lives. You optimize for the failures you've seen rather than the failures you're most likely to see next.
This shows up in runbooks that are detailed about the last three incidents and silent about the class of failure that's been quietly accumulating. It shows up in monitoring that's tuned to catch the specific error signatures from past outages but blind to the degradation patterns that precede them. It shows up in oncall rotations where the experienced engineers have a rich intuition about system behavior that lives entirely in their heads and nowhere in your documentation.
Reliability debt, in this sense, is an epistemological problem as much as a technical one. You don't know what you don't know, and you're not building the systems to find out.
The Practical Starting Point
You don't need a new tool. You don't need a new process framework. You need one person — ideally whoever runs your incident review — to spend thirty minutes a week asking a single question about the events that didn't make it into a postmortem: what would have had to be different for this to be a real incident?
That question is a forcing function. It makes the near-miss concrete. It surfaces the dependencies that almost mattered, the thresholds that almost tripped, the human decisions that happened to go right. And over time, it builds the kind of operational knowledge that doesn't show up in dashboards but absolutely shows up in mean time to recovery.
The incidents you're not writing down are the ones writing your next postmortem for you.