


You've seen this movie. The change passes every test. Staging looks clean. The deploy goes out on a Tuesday afternoon — low traffic, good timing, cautious team. Then something starts drifting. Not breaking, not alerting, just... drifting. By Thursday morning you're in a bridge call trying to explain why a change you shipped two days ago is only now causing problems.
The gap between staging and production isn't a tooling problem. It's a systems thinking problem. And most teams are still solving it with more tests when they should be solving it with better observability.
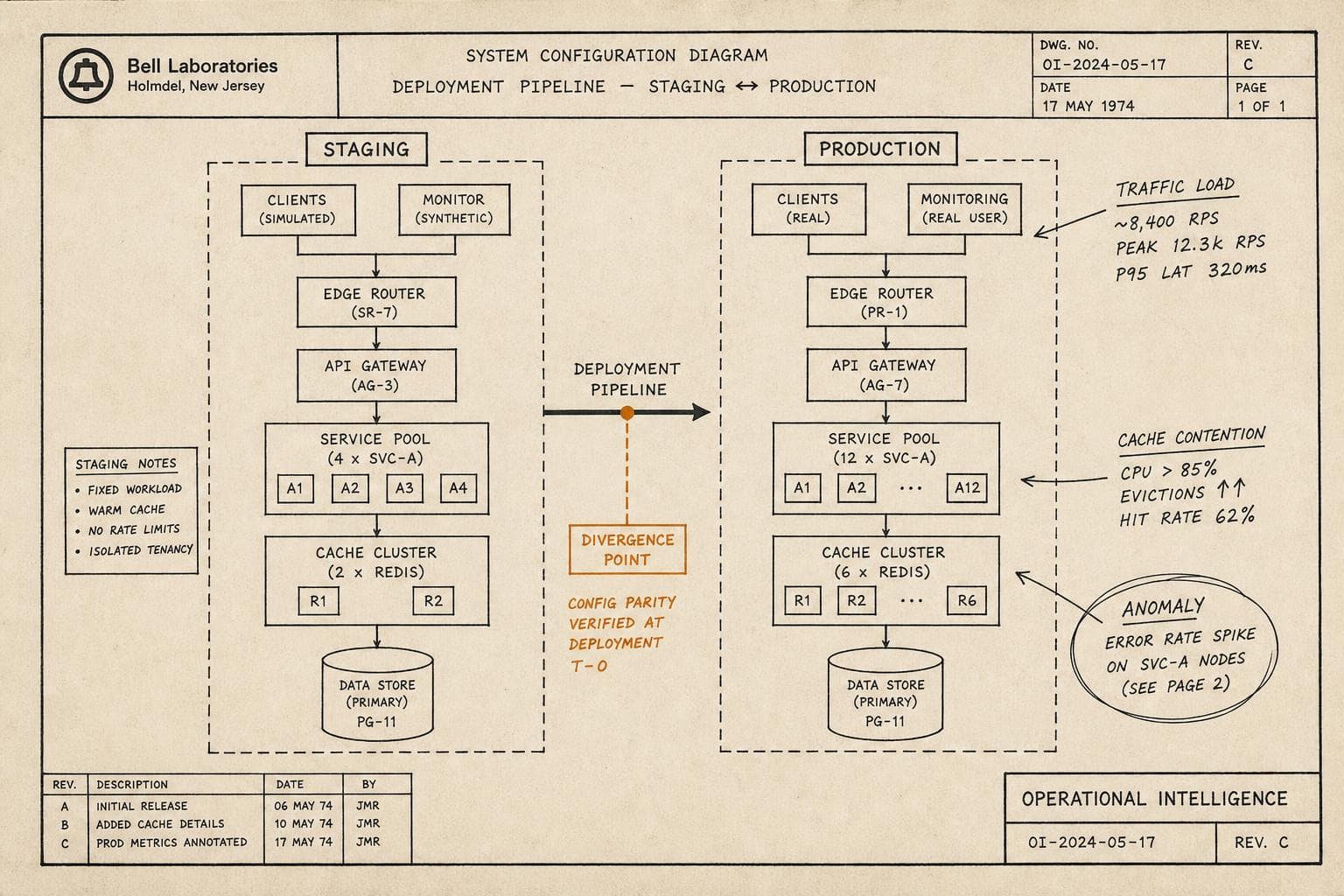
Staging Is a Model, Not a Mirror
Every staging environment is a simplification. It has to be — you can't replicate production traffic, production data volume, production user behavior, or the accumulated weirdness of a system that's been running for three years. What you can replicate is the shape of the system. And shape is not the same as behavior under load.
The failure mode this creates isn't the dramatic kind. It's the slow kind. A query that performs fine against 10,000 rows in staging starts degrading at 10 million. A cache that behaves predictably with synthetic traffic develops contention patterns under real access distributions. A third-party dependency that's always fast in staging has a bad day in production because production actually uses it at scale.
I'd argue the teams that handle this best aren't the ones with the most sophisticated staging environments — they're the ones who've stopped expecting staging to catch production failures and started instrumenting production to surface them early. The mental shift is from "prevent bad deploys" to "detect bad deploys fast and recover faster."
Canaries Do the Work Staging Can't
A canary deployment doesn't replace staging. It replaces the assumption that staging is sufficient. You ship to a small slice of real traffic, watch real signals, and make a real decision before the blast radius grows.
The operational discipline this requires is underrated. You need to know what "normal" looks like for that service before you can recognize "abnormal" in a canary. That means your baseline metrics have to be meaningful — not just "error rate is below 1%" but "p99 latency for this endpoint under this traffic pattern is typically X." Without that baseline, you're watching a canary and hoping you'll recognize a problem when you see one. That's not a strategy.
The teams that do this well define their canary success criteria before the deploy, not during it. What signals matter? What thresholds trigger a rollback? Who has authority to call it? If you're answering those questions while the canary is running, you've already lost some of the value.
The Recovery Path Is the Real Test
Here's the thing about deployment failures that postmortems consistently underscore: the deploy itself is rarely where the most time gets lost. The time gets lost in detection, in diagnosis, in the rollback decision, and in the rollback execution. A team that detects a bad deploy in two minutes and rolls back in five has a ten-minute incident. A team that detects it in forty minutes and spends another twenty debating whether to roll back has a different kind of problem.
This is where runbook quality matters — not as documentation theater, but as decision support under pressure. The rollback procedure for a given service should be so well-understood that the on-call engineer doesn't have to think about the mechanics. They should only have to think about the decision.
If your team has never actually practiced a rollback under realistic conditions, you don't know how long it takes. You have a theory about how long it takes. Those are different things.
What to Actually Do
Three practices that move the needle, in rough order of impact:
Define rollback criteria before you deploy. Not "we'll roll back if something looks bad" — specific thresholds, specific signals, specific decision authority. Write it in the deploy ticket.
Instrument the canary window explicitly. Don't just watch your existing dashboards. Create a view that shows canary vs. baseline side-by-side for the metrics that matter for this specific change. Generic dashboards during a canary are noise.
Run a rollback drill on a quiet day. Pick a non-critical service. Practice the full sequence: detect, decide, execute, verify. Time it. You will learn something uncomfortable, and that discomfort is worth more than any runbook update.
The deploy that works fine in staging and fails in production isn't a mystery. It's a predictable failure mode with a predictable mitigation. The teams that get paged less aren't the ones who've eliminated the gap between staging and production — they're the ones who've accepted it and built their recovery path accordingly.