Latest issue
The Queue Is the Feature: Why Your Fallback Chain Fails Before the Backup Model Fires
7/28/2026
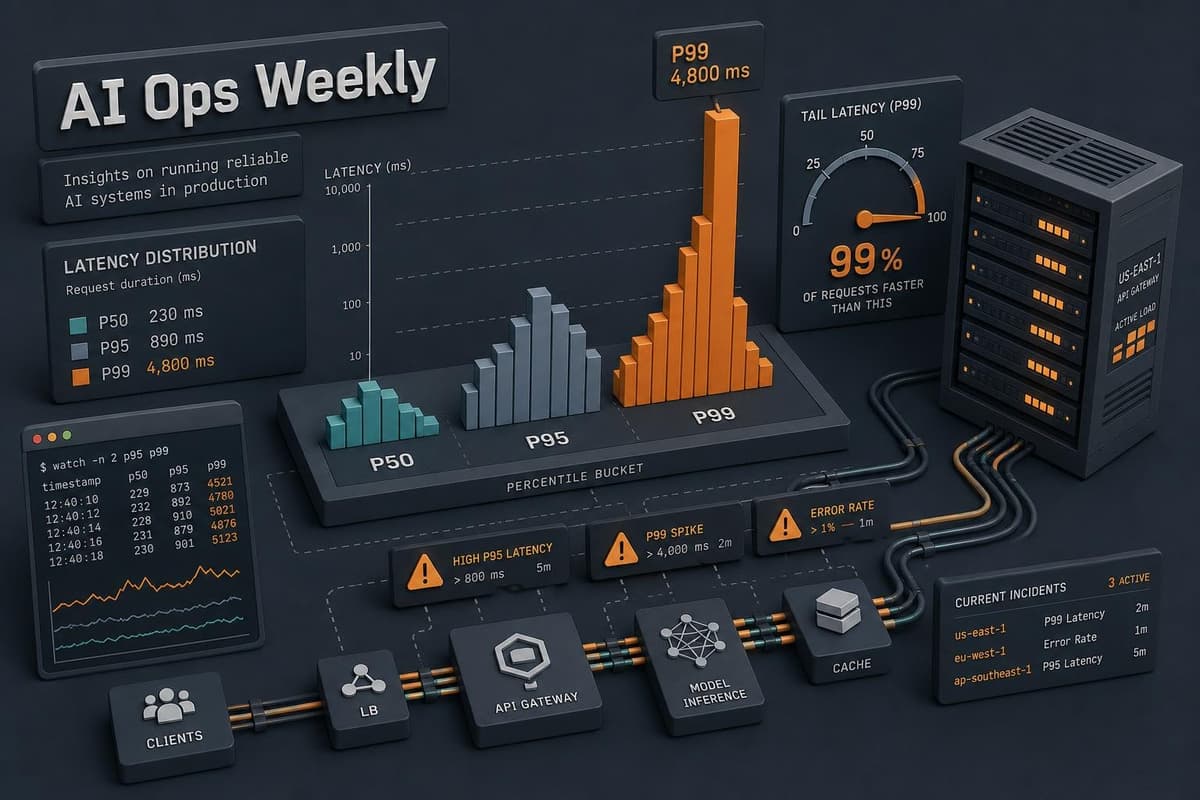
Most teams add a fallback model and call it done. Then they hit a 429 at 11am on a Tuesday, watch their retry logic turn one failed request into forty, and discover that "just add a backup model" was never actually the plan — it was the sketch of a plan. The real problem isn't wh…
Recent posts
A request comes in. The model returns something wrong. You open your logs and find: status: 200, latency: 1.4s, tokens: 847. Completely healthy. Completely useless. This is the def…
There's a specific failure mode I see constantly in production AI systems: a team sets a latency SLO, hits it consistently on their dashboards, and still gets user complaints about…
There's a specific kind of production incident that starts with a Slack message like "the extraction pipeline is returning nulls again." You dig in. The LLM returned valid JSON — s…
Most teams discover their LLM fallback strategy is broken at the worst possible moment: not during a 503 from a provider, but three steps later, when a downstream service starts be…
There's a specific kind of production incident that never pages anyone. The agent runs on schedule. Latency is flat. Costs are stable. HTTP 200s all the way down. And over six week…
A startup launched an AI research assistant. Their cost model said $0.04 per query. Their actual cost was $4.20 per session. By week three, they'd accumulated $67,000 in unexpected…
Most teams discover their LLM capacity plan is wrong at 2am, not during sprint planning. The bill looked fine. The projected monthly spend was within budget. Then a queue drained,…
Most teams have a deployment process for code. Peer review, staging environment, automated tests, rollback plan. The whole apparatus. Then someone edits a system prompt in a shared…
There's a specific production incident that doesn't announce itself. Your logs show HTTP 200s. Your monitoring reports zero errors. Your dashboard is green. And somewhere in your s…
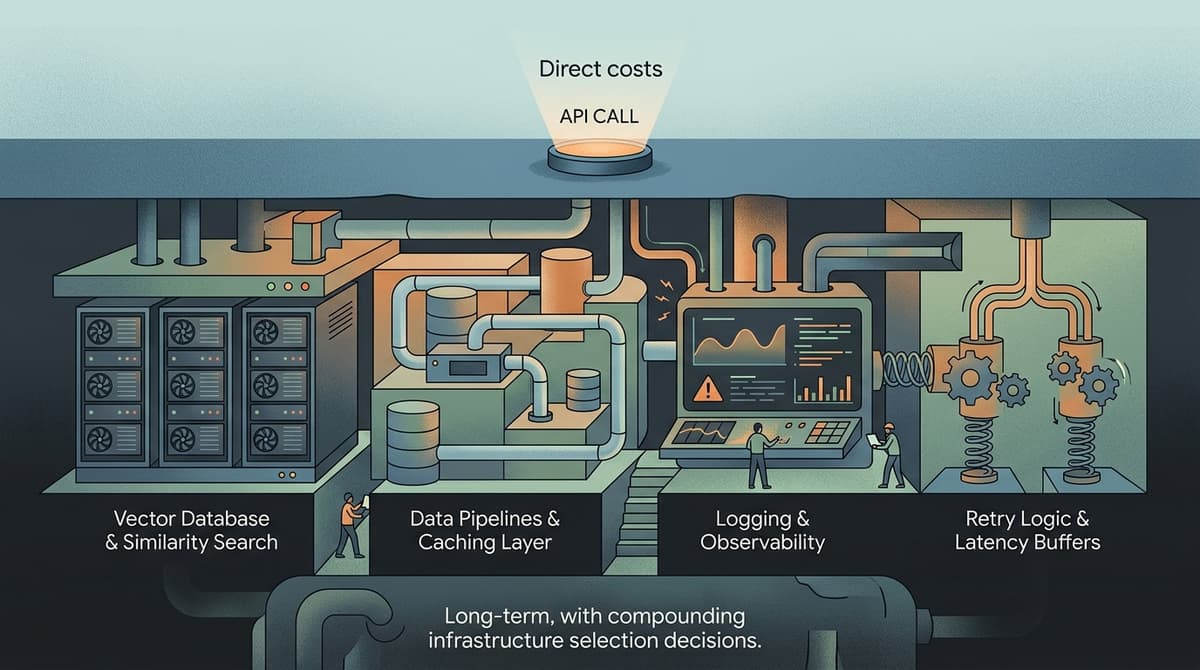
Most teams treating LLM cost as a model selection problem are solving the wrong equation. You can swap GPT-4o for a cheaper model and claw back 30% — or you can fix your caching ar…
The fintech team that added a single comma to their system prompt didn't know they'd broken anything. Their application kept running. Latency was normal. Error rate: zero. Their in…
Most small teams reach for fine-tuning the moment their prompts stop working. That instinct is expensive — and usually wrong. The decision between prompt engineering, fine-tuning,…
There's a specific kind of production incident that doesn't look like an incident. No pages fire. No error budgets burn. The status page stays green. But somewhere in the last six…
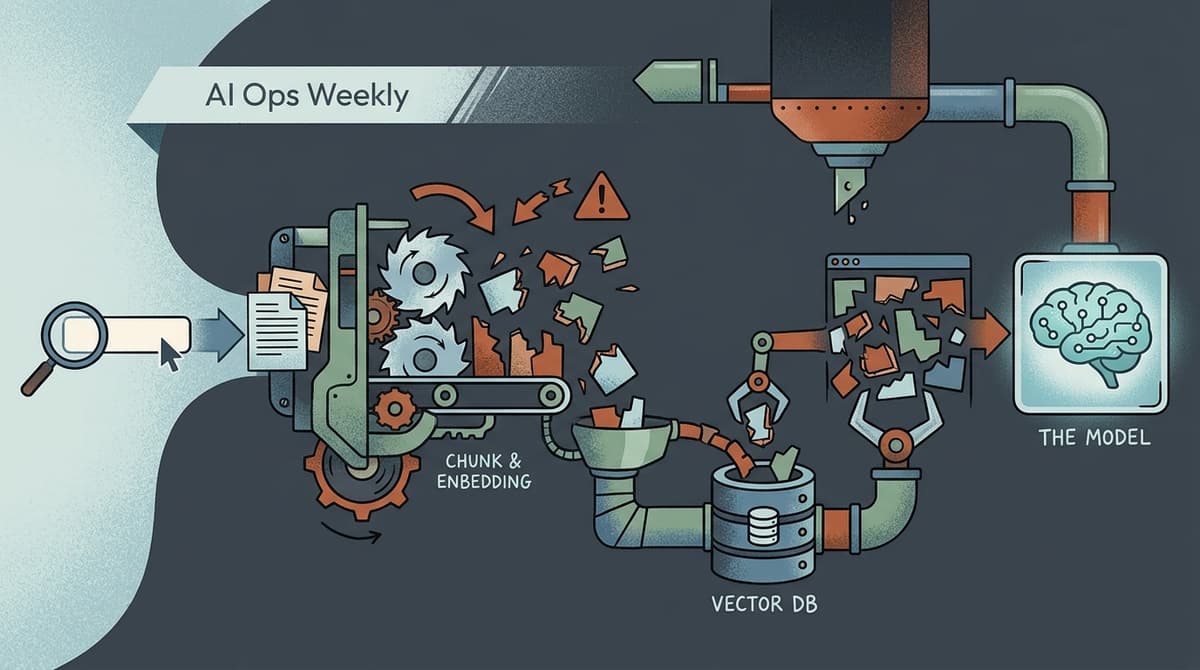
Here's the uncomfortable starting point: most teams shipping RAG systems have no idea what their retrieval quality actually is. They ship, collect vague user feedback, and assume t…
Your demo worked. The retrieval looked clean, the answers were coherent, and you shipped it. Then real users showed up with real questions, and the support tickets started. Wrong a…
Most teams discover they have a prompt regression problem the same way: a model provider quietly ships an update, outputs start drifting, and someone notices in a support ticket th…
Most teams budget for LLM costs by pulling up a pricing page and multiplying tokens by rate. That math isn't wrong — it's just incomplete by a factor of three or four, depending on…
There's a moment every team hits, usually around week three of a new model rollout, when someone pulls up the eval dashboard and says some version of: "But it scored higher on the…
A team ships a customer support bot with 94% accuracy on their internal test suite. Two weeks into production, escalations are up 40%. The model is fluent, latency is fine, HTTP 20…