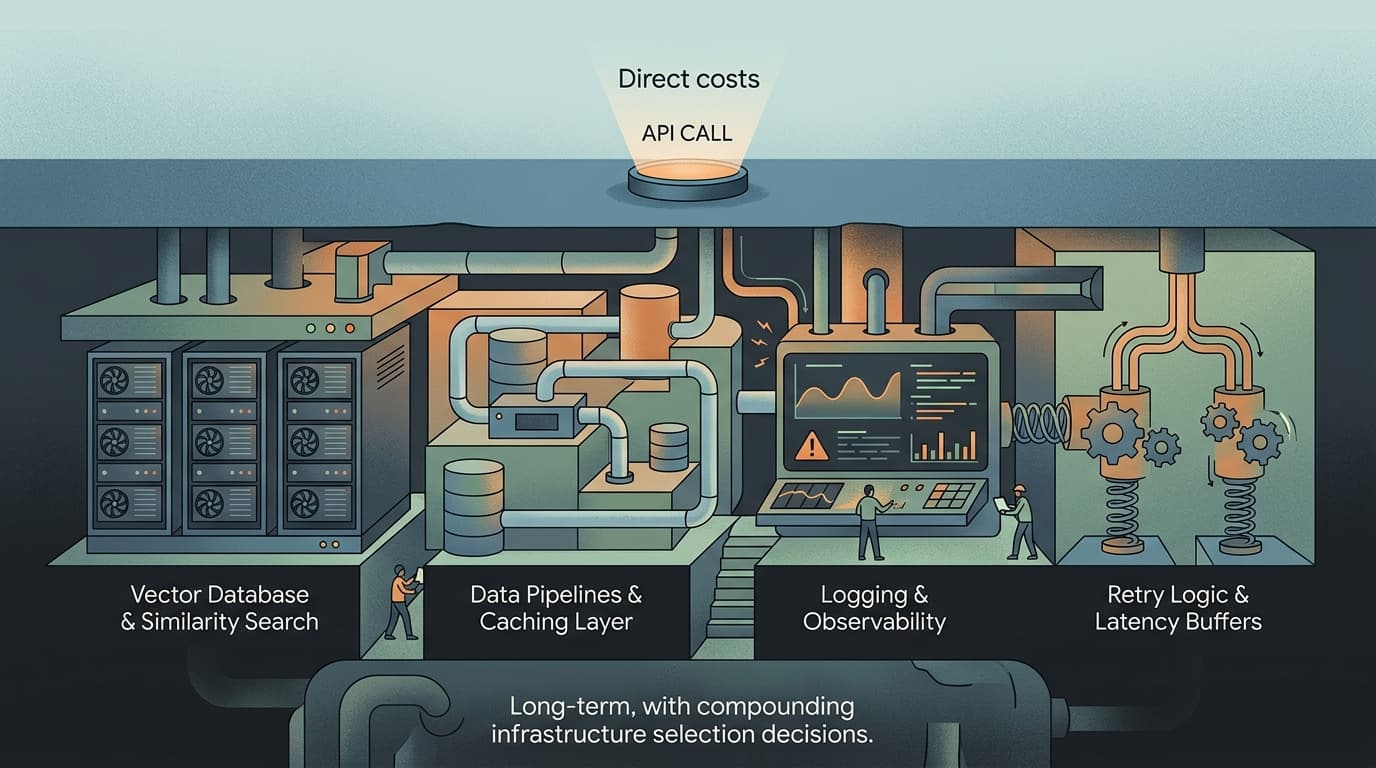
Most teams budget for LLM costs by pulling up a pricing page and multiplying tokens by rate. That math isn't wrong — it's just incomplete by a factor of three or four, depending on how your system is built.
The API bill is visible. The rest of the cost structure is not, and that's where small teams get surprised.
The Hidden Stack Underneath Every Inference Call
Take a straightforward production feature: a document summarization endpoint that handles a few thousand requests per day. The model cost is easy to calculate. Claude Sonnet 4.5 runs $3/1M input tokens and $15/1M output tokens — output being more expensive because it requires more compute. Plug in your token counts, you have a number.
What that number doesn't include: the vector database running similarity search before the prompt is assembled, the caching layer that may or may not be working, the logging infrastructure capturing every request for eval purposes, the retry logic burning duplicate tokens on transient failures, and the latency buffer you've built into your SLAs because the model occasionally takes eight seconds when users expect two.
Effective cost modeling requires identifying expenditure drivers beyond API call volumes — inference latency, compute usage, and the infrastructure selection decisions that compound over time. In practice, most teams don't do this modeling until they get a bill that doesn't match their spreadsheet.
The pattern I see repeatedly: a team estimates $800/month in API costs, ships the feature, and lands at $2,200/month once the full stack is running. Not because the model is expensive — because the model is surrounded by infrastructure that nobody priced.
Where the Actual Money Goes
Redundant tokens from poor prompt hygiene. System prompts that grew organically over three months of iteration often contain 400–600 tokens of redundant context. At scale, that's not a rounding error. A 500-token system prompt sent on every request at 100,000 requests/day is 50 million tokens monthly before a single user word is processed. Nobody budgeted for that because nobody audited it.
Caching that isn't working. Semantic caching — storing and reusing responses for semantically similar queries rather than exact matches — can meaningfully reduce both cost and latency at scale. The operational reality is that most teams implement exact-match caching, which has low hit rates for anything involving natural language. The cache exists; it just doesn't fire often enough to matter. The compute still runs.
Model routing that defaults to the expensive option. Routing simple tasks to smaller, faster models is one of the highest-leverage cost levers available — classification tasks, simple queries, and routine operations often work well with compact models, reserving larger models for complex reasoning. Most teams don't implement routing because it requires an evaluation framework to know which tasks are "simple." So everything goes to the capable model, and the capable model charges capable-model prices.
Observability overhead. Logging full request/response pairs for debugging and eval is necessary. It's also expensive at volume — storage, egress, and the tooling to make logs queryable. This cost is invisible until you're paying it.
The Systems Problem Underneath the Spend Problem
The reason LLM costs surprise teams isn't that the pricing is opaque — it's that the cost is distributed across a system, not concentrated in one line item. The API bill is the most legible part. The infrastructure surrounding it is a collection of decisions made by different people at different times, none of whom were thinking about the aggregate cost.
That's a systems problem. The fix isn't to negotiate better API rates (though the gap between AI infrastructure investment and revenue is real and growing, which will eventually pressure providers). The fix is to instrument the full stack before you scale it — token counts per component, cache hit rates, model routing distribution, retry frequency — so you know what you're actually buying.
The teams that get this right treat LLM cost as an engineering metric, not a finance problem. They have dashboards. They set alerts. They run quarterly prompt audits the same way they run dependency audits. It's not glamorous. It's just what keeps a $800 estimate from becoming a $2,200 bill.
Eval Patterns
Audit your system prompts on a schedule, not just when something breaks. Token bloat in system prompts is one of the most common sources of cost drift — instructions accumulate, context gets added, nothing gets removed. A quarterly pass to strip redundant instructions and consolidate overlapping context is worth doing. Measure token counts before and after; the delta is usually larger than expected.
Separate your eval dataset by task complexity. If you're considering model routing, you need labeled examples of "simple" vs. "complex" queries to validate that the routing logic is correct. Build that dataset before you build the router, not after.
Reliability Notes
Retry logic needs token accounting. A naive retry on timeout will resend the full prompt, doubling your token spend on that request. Implement exponential backoff with jitter, and log retry events as a distinct metric. If your retry rate climbs above a few percent, that's a signal worth investigating — either the model is degraded or your timeout thresholds are too aggressive.
Cache invalidation strategy matters more than cache implementation. Semantic caching works well for stable query patterns; it degrades when your underlying data changes and cached responses go stale. Define a TTL policy before you ship, not after users start getting outdated answers.
Cost Watch
The highest-ROI optimization most teams skip: model routing. Sending every request to a frontier model when a smaller model handles 60–70% of your query volume correctly is a straightforward cost problem with a straightforward solution. The blocker is usually the eval work required to validate routing accuracy. Budget two to three weeks of engineering time to build the classifier and evaluation set — the payback period at any meaningful request volume is short.
Watch for output token inflation in agentic workflows. Multi-step agent loops generate output tokens at every step, and those outputs often become input context for the next step. Cost compounds in ways that single-turn pricing estimates don't capture. If you're building or scaling an agent feature, model the full loop cost, not the per-call cost.


