Your demo worked. The retrieval looked clean, the answers were coherent, and you shipped it. Then real users showed up with real questions, and the support tickets started. Wrong answers. Missed context. Confident hallucinations on documents that were definitely in the knowledge base.
The instinct is to blame the model. The model is almost never the problem.
What breaks is the plumbing between the user's question and the context the model actually receives. Fix that plumbing, and most RAG failures disappear. Leave it alone, and no amount of prompt tuning will save you.
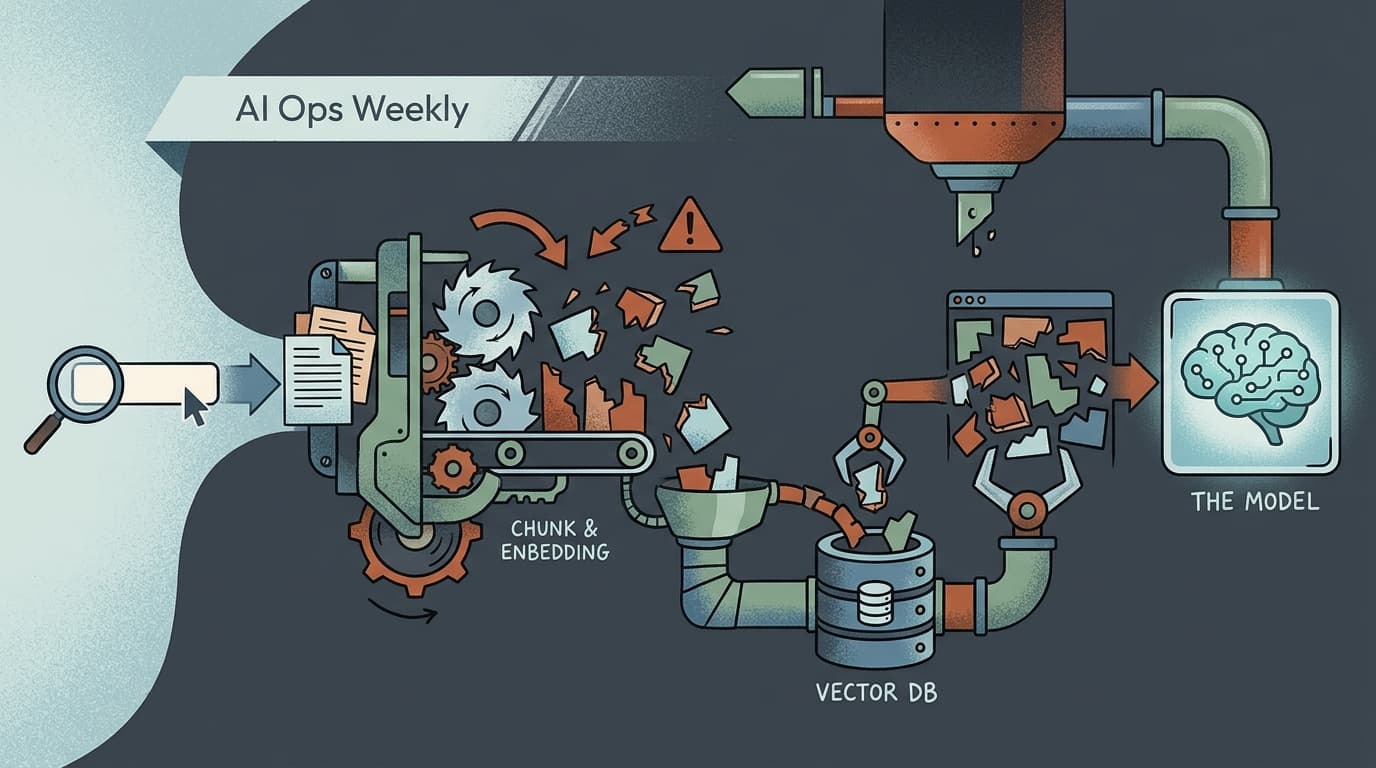
The Failure Starts at Chunking, Not Retrieval
The default RAG setup — fixed-size text splits, vector DB, top-K retrieval — works well enough in a notebook. In production, fixed-size chunking is where information loss begins, before retrieval even runs.
The problem is mechanical: a fixed character or token boundary doesn't know where a sentence ends, where a concept completes, or where a table row breaks. You end up with chunks that contain half an answer, or that split a key fact across two chunks that never get retrieved together. The retrieval layer then does exactly what you asked — finds the most semantically similar chunks — and hands the model a context window full of fragments.
One analysis of production RAG architectures frames this as the highest-leverage fix most teams skip: proposition-based or semantic chunking, which respects document structure rather than imposing arbitrary boundaries. The cost is minimal compared to adding a reranker downstream. The impact on retrieval quality is substantial.
The second chunking mistake is ignoring metadata. Chunks without document titles, section headers, or timestamps are semantically orphaned. The model can't reason about source authority or recency. For any knowledge base where documents conflict or go stale, that's a silent accuracy problem.
Raw Queries Are the Second Place Things Break
Most teams send the user's raw query directly to the vector database. That's a mistake for a predictable reason: users don't phrase questions the way documents phrase answers.
A user asks "what's our refund window for enterprise contracts?" The relevant document says "enterprise agreements include a 30-day cancellation clause." The semantic distance between those two phrasings is real, and it costs you retrieval hits.
Query transformation — rewriting or expanding the user's question before it hits the retrieval layer — closes that gap. Hypothetical document embedding (HyDE) generates a synthetic answer and embeds that instead of the raw question, which often retrieves better than the question itself. Multi-query expansion generates several phrasings of the same question and merges the results. Neither approach is expensive. Both meaningfully improve recall on ambiguous or conversational queries.
The pattern that practitioners building production systems consistently flag: teams over-engineer the retrieval stack — adding rerankers, tuning similarity thresholds — while leaving query transformation completely untouched. You can spend a week tuning a reranker and recover less ground than a single query rewriting step would have given you for free.
Hybrid Search Isn't Optional at Scale
Pure semantic search misses exact matches. A user searching for a specific product SKU, a contract clause number, or a person's name gets back semantically adjacent results instead of the literal match they need. Production benchmarks show why 72% of production RAG systems now combine dense vector search with sparse keyword retrieval (BM25 or equivalent): neither approach alone handles the full range of real queries.
The operational implication is that your vector database choice matters more than teams typically realize at architecture time. Weaviate has BM25 hybrid search built into the query engine. Qdrant supports hybrid natively. ChromaDB is fine for prototyping but degrades at scale — the same benchmarks put ChromaDB at 18ms p50 latency at 1M vectors, compared to 6ms for Qdrant, with steeper degradation as corpus size grows. If you're on ChromaDB in production above a few million vectors, that's a migration worth scheduling.
Eval Patterns
The most common RAG evaluation failure is "vibe checking" — manually reading a sample of outputs and calling it good. What you need instead: faithfulness scoring (does the answer contradict the retrieved context?), context recall (did retrieval surface the right documents?), and latency per percentile, not just average. RAGAS is the most widely adopted open-source framework for this. Run it on a fixed golden dataset after every chunking or retrieval change. If you don't have a golden dataset yet, building one from your actual support tickets is the fastest path to something meaningful.
Reliability Notes
Retrieval confidence needs a fallback path. When your retrieval layer returns low-similarity results — nothing above your threshold — the model should say so rather than hallucinate from weak context. Implement a confidence gate: if max similarity score is below a defined threshold, route to a fallback response or escalate to a human. CRAG (Corrective RAG) formalizes this with a retrieval evaluator that decides whether to use, refine, or discard retrieved context before generation. For teams without the bandwidth to implement full CRAG, a simple similarity threshold check catches the worst cases.
Cost Watch
Rerankers are the hidden cost multiplier in RAG. Cross-encoder rerankers improve precision meaningfully, but they run inference on every candidate chunk — at 20 retrieved candidates per query, you're paying for 20 model calls before the generation step. For high-volume pipelines, profile your reranker cost separately from generation cost. Many teams find that better chunking and query transformation reduce the number of candidates needed, which cuts reranker spend without sacrificing quality. The fix that costs nothing often outperforms the fix that costs per token.


