


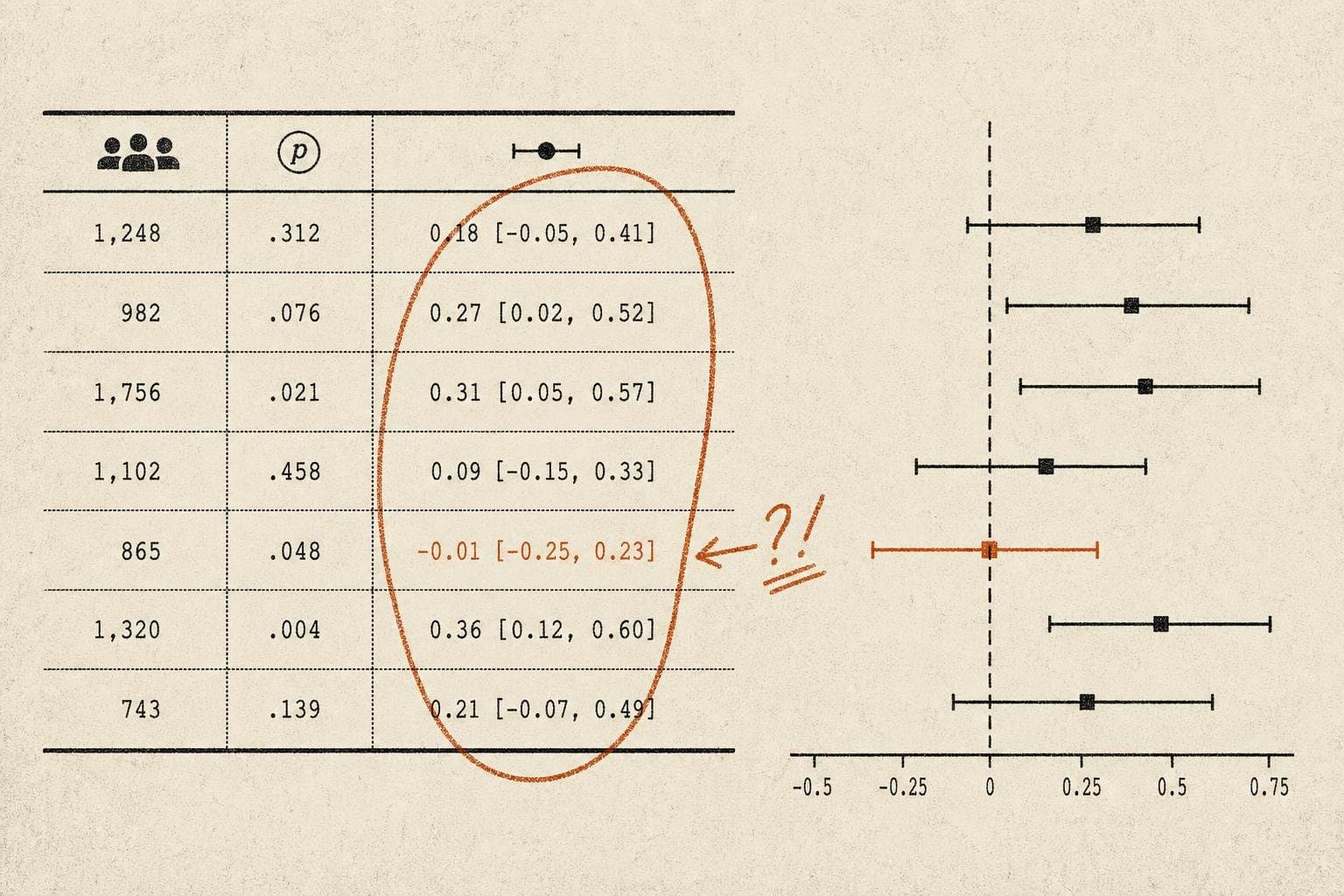
A clinical trial enrolls a thousand patients. The new antidepressant beats placebo. The p-value is 0.03 — statistically significant, publishable, press-releasable. The drug reduces symptom scores by 1.2 points on a 52-point scale.
That's the gap between what a study demonstrates and what it claims. And in medical research, that gap has been swallowing patients for decades.
Significance Is a Binary Switch on a Continuous World
The p-value answers one narrow question: assuming the null hypothesis is true (no effect), how likely is it that you'd see data at least this extreme by chance? Cross the 0.05 threshold and the result is "significant." Stay above it and the result is "null." The entire apparatus of publication, funding, and clinical adoption has been built on that binary.
The problem is that statistical significance says nothing about magnitude. A trial with 50,000 participants can detect effects so small they're clinically meaningless — the math almost guarantees it. A trial with 80 participants might miss a genuinely important effect because it was underpowered. The p-value conflates sample size with signal strength, and most science journalism never untangles them.
Effect size — the actual magnitude of the difference between groups — is what clinicians and patients need. A drug that reduces blood pressure by 1 mmHg in a massive trial can achieve p < 0.001 while doing essentially nothing for any individual patient. A drug that reduces it by 15 mmHg in a smaller trial might show p = 0.06 and get filed away as a failure.
Ioannidis's 2005 paper in PLOS Medicine made the deeper version of this argument: the structural conditions of research — small samples, flexible analyses, publication bias toward positive results — mean that many "significant" findings are probably false positives regardless of what the p-value says. The math was Bayesian and elementary. The conclusion was that prior probability matters enormously, and that a p-value of 0.04 in a low-prior-probability field is much weaker evidence than it looks. That paper has been cited in tens of thousands of subsequent studies, which tells you something about how widely the problem is recognized and how slowly the practice has changed.
The Hacking Problem Makes It Worse
Statistical significance is already a fragile signal. Then add the incentive to cross the threshold.
A new preprint on arXiv takes a hard look at p-hacking detection — the practice of examining distributions of reported t-statistics for telltale bunching just below the significance cutoff. The finding is uncomfortable: some forms of selective reporting are undetectable by examining those distributions. When the distribution of true effects is sufficiently smooth, it can provide cover for selective reporting. The hacked p-curve has, as the authors put it, an "alibi."
The paper does propose a sharper test — one designed to detect every form of selective reporting that any valid test based on t-statistics could catch. Applying it to a large meta-dataset of economics studies, they find that distributions for randomized controlled trials and instrumental variable studies are more distorted than could arise by chance. That's economics, not medicine. But the methodological point travels: the standard tools for catching p-hacking may be systematically underpowered, and some manipulation may be genuinely invisible to current detection methods.
This isn't an argument that researchers are mostly fraudsters. It's an argument that the incentive structure — publish significant results, bury null ones — creates systematic pressure that distorts the literature even when no individual researcher is acting in bad faith.
What Should Replace the Threshold?
The honest answer is that nothing cleanly replaces it, which is part of why the 0.05 convention has survived decades of criticism. Effect sizes with confidence intervals are more informative than p-values alone, but they require readers to have some sense of what a meaningful effect looks like in a given domain — knowledge that varies by field and rarely travels well in press releases.
Nature's recent expansion of Registered Reports to all fields it publishes is one structural response worth watching. The format requires researchers to submit hypotheses and analysis plans for peer review before collecting data, and commits the journal to publish the results regardless of outcome. That directly attacks the file-drawer problem — the tendency for null results to disappear — and removes the incentive to fish for significance after the fact. The first completed Registered Report in Nature came from a study of social media algorithms during the 2024 US election. The expansion to all fields is new.
That's a methodological reform that operates upstream of the p-value debate entirely. It doesn't fix how significance is interpreted, but it changes what gets submitted in the first place.
The p-value problem has been diagnosed so many times that the diagnosis itself has become a kind of ritual. What's harder — and what the Registered Reports expansion is actually attempting — is redesigning the incentives that make the threshold so irresistible to begin with. Watch whether other high-impact journals follow Nature's lead in the next publication cycle. That's the signal worth tracking.