


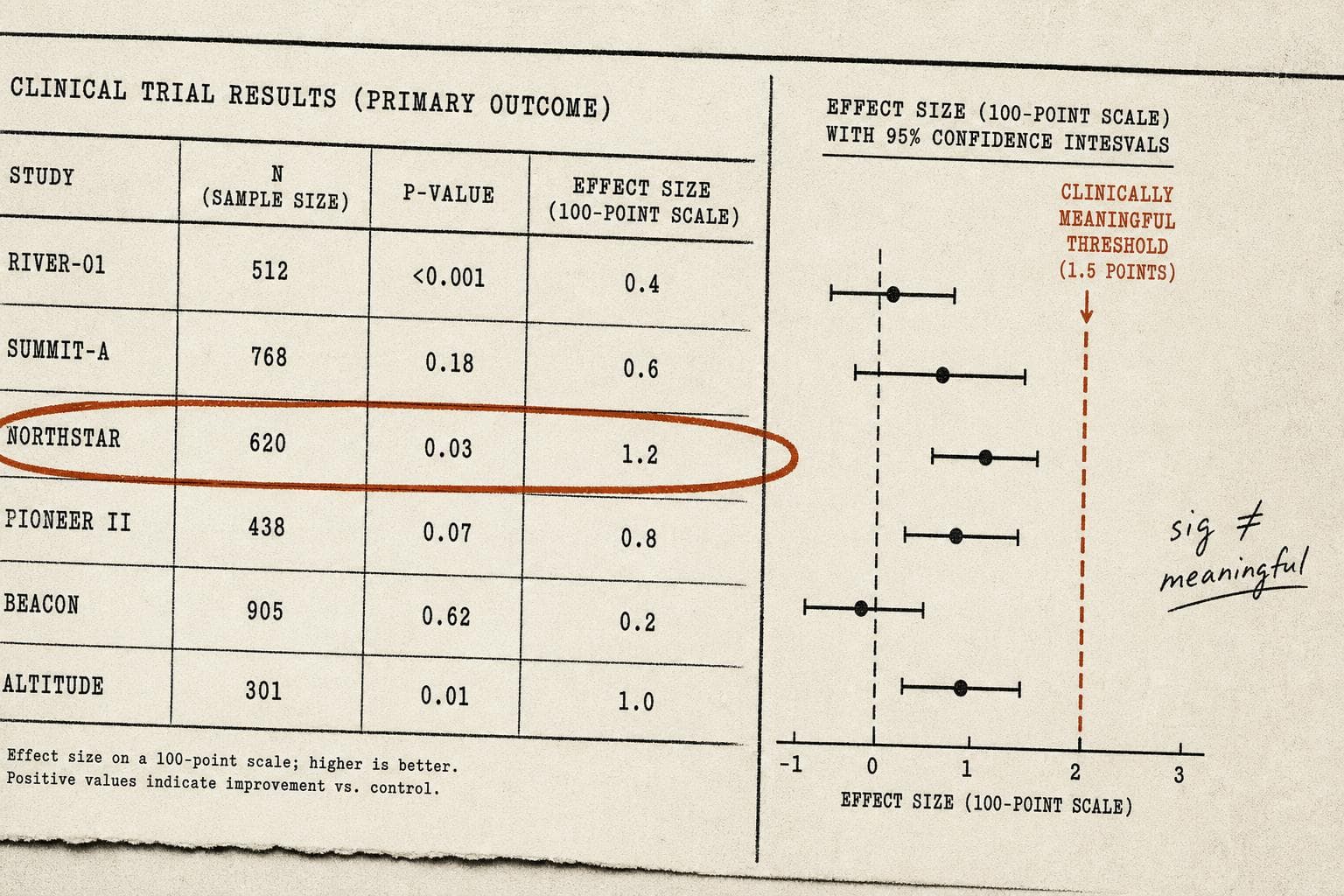
A trial enrolls 800 patients. The new drug reduces symptom scores by 1.2 points on a 100-point scale. The p-value is 0.03. The press release says: "statistically significant results." The headline says: "Breakthrough."
Nobody mentions that the clinical threshold for a meaningful improvement — the point at which a patient would actually notice a difference — is 10 points.
This is the gap that doesn't make headlines, and it's worth understanding precisely because it's so easy to miss.
The Math Works. The Medicine Doesn't.
Statistical significance answers one narrow question: given this data, how likely is it that the observed effect is just random noise? A p-value below 0.05 says, roughly, "probably not noise." It says nothing about whether the effect is large enough to matter to a patient.
The confusion runs deeper than semantics. A recent arXiv preprint reviewing how to interpret randomized controlled trials flags a specific trap: underpowered studies — those with small samples — tend to inflate initial effect estimates by 25–50%, citing Button et al.'s 2013 work in Nature Reviews Neuroscience. The same paper warns directly against using small-trial effects as the basis for confirmatory power calculations. In other words, the studies most likely to produce dramatic-looking numbers are also the ones least equipped to tell you whether those numbers are real.
This creates a perverse dynamic. A small trial finds a large effect. That large effect gets used to power the next, bigger trial. The bigger trial finds a smaller — more realistic — effect. Which may still be statistically significant. Which may still be clinically meaningless.
Exploratory Analyses Make It Worse
A new piece in Nature Communications (2026) gets at another layer of the problem. Researchers Dr. Nancy Butcher and Dr. Anna Heath, along with cancer researcher Dr. Silvia Marsoni, draw a distinction between prospectively declared analyses — the ones a trial was actually designed to test — and exploratory analyses, which are essentially post-hoc pattern searches through the data.
Exploratory analyses aren't inherently bad. They generate hypotheses. They surface unexpected signals. But they carry a serious false-positive risk that often goes unacknowledged when results get reported. The more comparisons you run through a dataset, the more likely you are to find something that clears the p < 0.05 bar by chance alone. Run enough subgroup analyses and you'll eventually find that the drug works — but only in left-handed women over 60 who enrolled in the trial on a Tuesday.
The problem isn't that researchers do this. The problem is that exploratory findings frequently get reported with the same confidence as primary outcomes, and the distinction rarely survives the journey from journal to press release to headline.
The Missing Data Problem Compounds Everything
There's a third layer. The FDA recently sent over 2,200 letters pressing drug manufacturers, device makers, and researchers to publish clinical trial data they've been sitting on. The NYT reported that many unfavorable results go unreported, systematically skewing the available evidence on medical treatments.
This matters for the statistical significance question because the published literature is not a random sample of all trials conducted. It's a curated selection tilted toward positive results. When you read a meta-analysis concluding that a treatment works, you're reading a synthesis of the studies that made it to publication — not the full picture of what was tested. The effect sizes in that meta-analysis are probably inflated. The confidence intervals are probably too narrow. The clinical meaningfulness of the finding is probably overstated.
I'd argue this is the most underreported structural problem in evidence-based medicine. It's not fraud. It's not even necessarily bad faith. It's the predictable output of a system where positive results get published and negative results get filed away.
Meta-Science Moment: The Threshold Nobody Agrees On
Here's the uncomfortable part: "clinically meaningful" isn't a fixed number. It's a judgment call, and different stakeholders make it differently. Regulators, clinicians, patients, and payers often have different thresholds for what counts as a meaningful benefit — and those thresholds are rarely made explicit in trial design or reporting. A 1.2-point improvement might matter enormously to one patient population and be irrelevant to another. Statistical significance papers over that ambiguity rather than resolving it.
Bottom Line: A p-value below 0.05 means the effect probably exists. It does not mean the effect matters. The gap between those two statements is where a lot of medical decision-making quietly goes wrong — and where the next wave of methodological reform needs to focus. Watch for whether the FDA's data-publication push actually changes what gets reported, or just adds paperwork to the same selective process.