


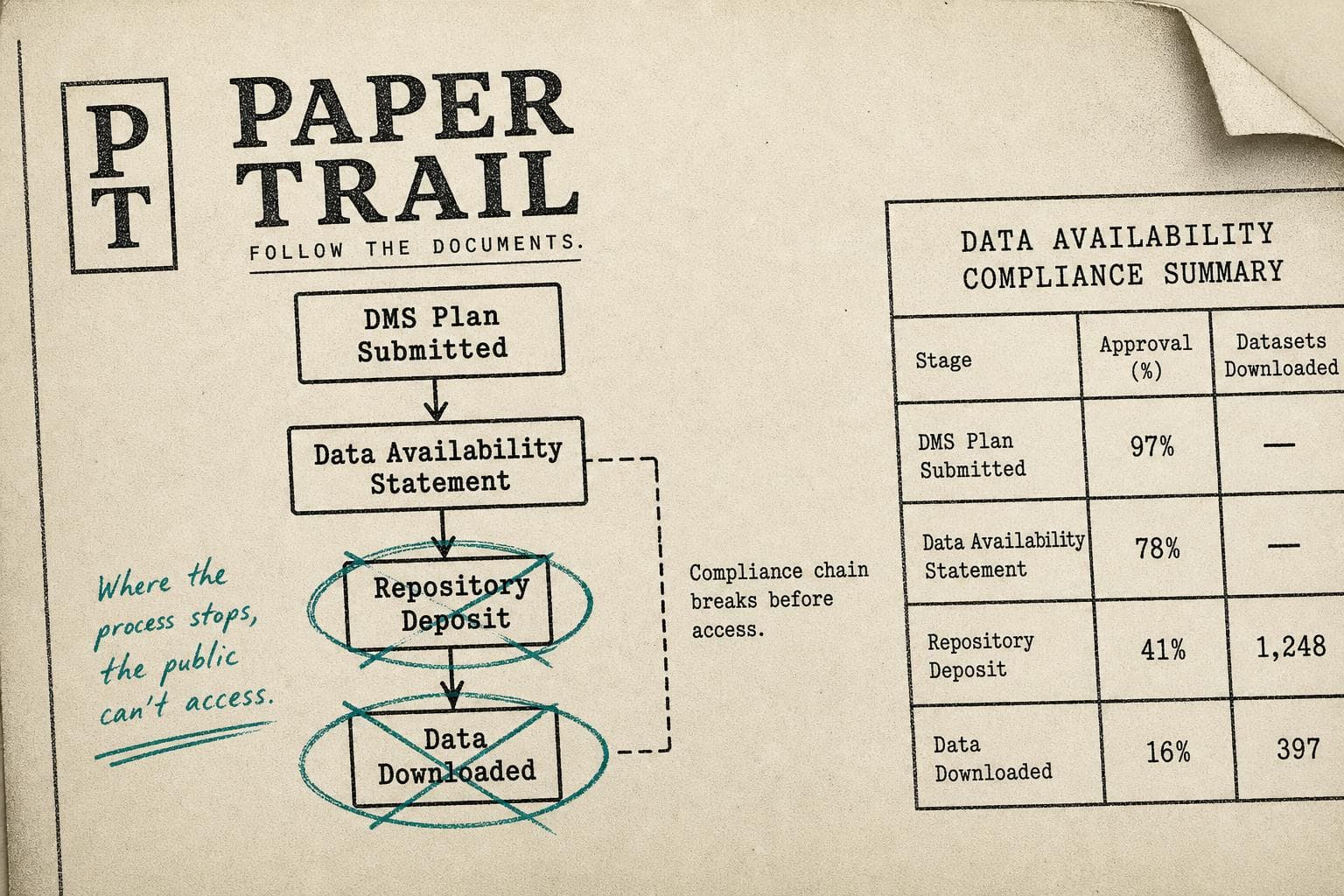
There's a version of open science that exists entirely on paper. Journals adopt data availability policies. Funders mandate sharing plans. Researchers check the box. And then, somewhere between submission and the archive, the actual data quietly fails to appear.
This gap between policy and practice has been documented before — but two developments from the past two weeks sharpen the picture considerably, and together they suggest the problem is structural rather than accidental.
The Compliance Theater Problem
Start with the NIH. On May 25, the agency retires its old narrative Data Management and Sharing Plan format and replaces it with a structured checklist — yes/no questions, a short table, no more two-page prose essays that buried the actual commitments in boilerplate. The reason for the change is instructive: after reviewing more than 1,100 plans submitted since the 2023 policy launched, NIH concluded the old format was producing "more noise than signal." Researchers were padding their plans with copied repository descriptions and vague future-tense intentions. Even a careful reviewer couldn't quickly answer the four questions that actually mattered: Will this researcher share the data? When? In what repository? Under what access conditions?
That's a remarkable admission. The agency spent three years collecting data-sharing commitments and apparently couldn't reliably tell, from the documents themselves, whether researchers intended to share anything. The new checklist format is an attempt to fix the form. Whether it changes the underlying behavior is a different question entirely.
What "Available Upon Request" Actually Means
The structural problem is that data availability statements — the ones journals require at submission — and data management plans exist in separate bureaucratic universes. A researcher writes a DMS Plan for their grant application, then writes a data availability statement for their manuscript, and the two documents may describe entirely different intentions without anyone noticing. The NIH's own guidance explicitly flags this disconnect as something researchers should think through, which suggests it's not being thought through very often.
Meanwhile, a new arXiv preprint attempts to measure what actually happens after those statements are written. The paper, submitted to the Annual Conference on Science and Technology Indicators, describes an AI-assisted system for detecting whether published papers actually reuse or link to shared datasets — essentially trying to build an empirical audit of open science claims at scale. The methodology is preliminary, and the paper is not yet peer-reviewed. But the underlying question it's trying to answer is the right one: not "did the journal have a data sharing policy?" but "did the data actually get shared and used?"
That distinction matters more than it might seem. A journal can have a mandatory data availability policy and still publish hundreds of papers per year where the data availability statement reads "available upon reasonable request" — a phrase that research has repeatedly shown functions as a near-total barrier to access in practice. Requiring a statement is not the same as requiring data.
One Counterexample Worth Noting
Against this backdrop, a paper published in Aperture Neuro on May 5th is worth examining as a concrete case of what genuine data sharing looks like operationally. The A4 and LEARN Alzheimer's trials released longitudinal neuroimaging data — MRI, amyloid PET, tau PET — through a formal request system. Between December 2018 and May 2025, 1,907 data requests were submitted, with 91.3% approved. Of those approved users, 179 actually downloaded neuroimaging data.
That last number is the one I keep returning to. Of roughly 1,741 approved requests, 179 resulted in downloads. That's not a failure of the sharing system — the data was genuinely available, the approval rate was high, and the infrastructure worked. It's a reminder that "data available" and "data used" are different outcomes, and that building the archive is only part of the problem.
The Bottom Line
The NIH format change is real, and the intent behind it is legitimate: make commitments legible enough to hold researchers accountable. But legibility is a precondition, not a solution. The pattern across these developments points toward the same underlying issue — open science policy has outpaced open science infrastructure, and the gap is being papered over with statements rather than closed with systems. Watch whether the May 25 rollout produces measurable changes in data deposit rates; that's the number that will tell you whether the checklist accomplished anything the narrative didn't.