


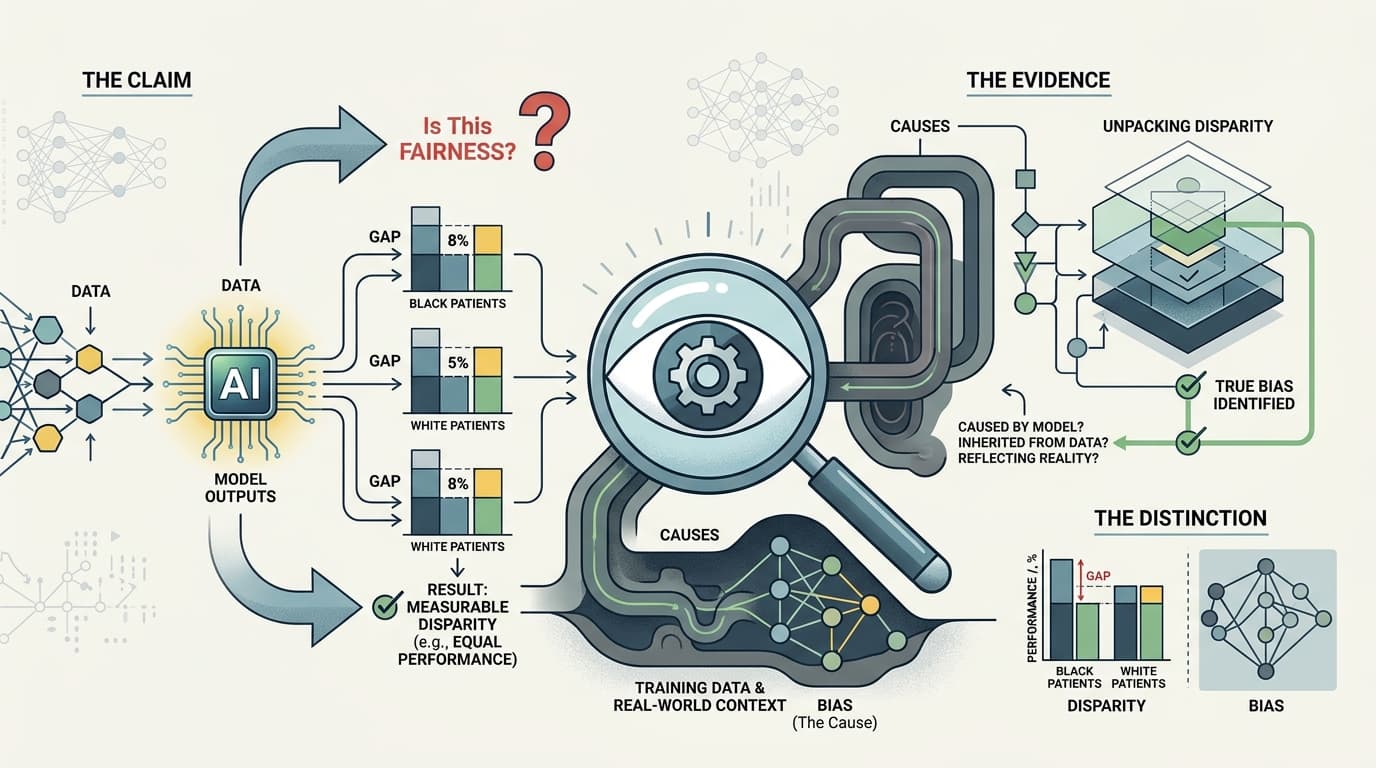
Most AI bias research doesn't actually study bias. It studies disparity — and those are not the same thing.
Here's the distinction that gets quietly buried in methods sections: a disparity is a measurable difference in outcomes across demographic groups. Bias is a cause of that disparity. When a study reports that a model performs 8 percentage points worse on Black patients than white patients, that's a disparity finding. Whether the model caused that gap, inherited it from training data, or is accurately reflecting an underlying clinical reality that itself reflects historical inequity — that's a different question entirely, and most fairness studies don't answer it.
The Claim
The standard AI fairness study runs something like this: take a deployed or benchmark model, stratify its outputs by race, sex, or age, measure performance metrics across groups, report the gaps. Conclude that the model is or isn't "fair." The framing implies that if you can demonstrate equal performance across demographic categories, you've solved the bias problem.
This is a methodologically coherent thing to measure. It's just not what the headlines say it is.
The Evidence
The problem lives in what these studies treat as ground truth. To measure whether a model performs equally well across groups, you need a reference standard — a correct answer to compare against. In medical AI, that reference standard is usually clinician diagnosis, prior test results, or structured EHR data. All of which carry their own demographic skews.
A recent Nature Medicine perspective on clinical AI evaluation makes this point directly: static benchmarks fail to capture the dynamic, context-dependent nature of clinical decision-making, and evaluation frameworks that don't account for how ground truth was generated will systematically mischaracterize model performance. If the training labels were produced by a healthcare system that historically under-diagnosed pain in Black patients, a model that matches those labels perfectly is replicating that pattern — and a fairness audit comparing performance across groups will miss it entirely, because the model looks equally "accurate" by the only standard being applied.
There's a related problem in recent work on foundation models in medical imaging: models trained on large imaging datasets retain latent demographic signals even when explicit demographic variables are excluded. Re-identification rates from retinal imaging reached as high as 94% in one cited study. The implication for fairness research is uncomfortable — if a model has effectively encoded race and sex from imaging features alone, then a fairness audit that withholds demographic labels from the model isn't actually testing a demographically-blind system. It's testing a system that inferred those variables anyway.
The Reality
None of this means AI fairness research is useless. Disparity measurement is a legitimate starting point. The problem is when it's treated as the finish line.
The deeper methodological issue is that "fairness" in this literature is not a single concept — it's a family of competing mathematical definitions that are, in many cases, provably incompatible with each other. Equalizing false positive rates across groups and equalizing predictive value across groups cannot both be achieved simultaneously when base rates differ between groups. This isn't a fixable software problem. It's a mathematical constraint. Every fairness study makes an implicit choice about which definition to prioritize, and most don't flag that choice as a choice.
What would better research look like? It would specify which fairness criterion it's applying and why. It would interrogate the ground truth labels, not just the model outputs. It would distinguish between a model that performs differently across groups because it's wrong and a model that performs differently because the underlying data distribution differs. And it would be honest about the fact that "fair" is a value judgment that precedes the math — the equations don't tell you what to optimize for.
Bottom Line
The next time you see a headline about an AI system being certified as fair, or condemned as biased, find the methods section. Ask what definition of fairness they used, where the ground truth came from, and whether the study can distinguish a model that causes disparity from one that reflects it. If those questions aren't answered, the study has measured something — just not what it claims.