Lesson 15: What Erlang's actor model teaches us about building systems that expect to fail
A telephone switch that handles 30–40 million calls per week cannot afford a maintenance window. It cannot queue a restart for off-peak hours. When something breaks — and in a system that large, something always breaks — the system has to heal itself while the calls keep flowing.
That's the problem Erlang was built to solve. And the solution it landed on was philosophically strange enough that most programmers still misread it decades later.
Joe Armstrong's 2003 paper on concurrency-oriented programming describes the AXD301, an Ericsson ATM switch with 1.7 million lines of Erlang and a measured reliability of 99.9999999% — nine nines, corresponding to roughly 31 milliseconds of downtime per year. That number isn't a marketing claim about Erlang's quality. It's evidence of what happens when you design a system around the assumption that individual components will fail, and build recovery into the architecture rather than trying to prevent failure entirely.
The Problem Wasn't Concurrency. It Was the Wrong Mental Model for Concurrency.
Before Erlang, the standard approach to concurrent systems was shared memory protected by locks. The reasoning was intuitive: if multiple processes need to work with the same data, give them access to it and coordinate that access with semaphores or mutexes.
Armstrong's paper is blunt about why this fails at scale. Sharing data doesn't just create coordination overhead — it creates coupling. When one process holds a lock and crashes, other processes waiting on that lock are now stuck. The failure of one component becomes the failure of many. The system's fault boundary is as wide as its most shared resource.
Erlang's answer was to eliminate shared state entirely. Erlang processes have share-nothing semantics: each process has its own heap, communicates only through message passing, and cannot directly touch another process's memory. The consequence Armstrong highlights is almost counterintuitive — this improves efficiency rather than degrading it, because you've removed the coordination overhead that shared memory requires.
But the deeper consequence is architectural. When processes share nothing, a crash is contained. The failure boundary is exactly one process.
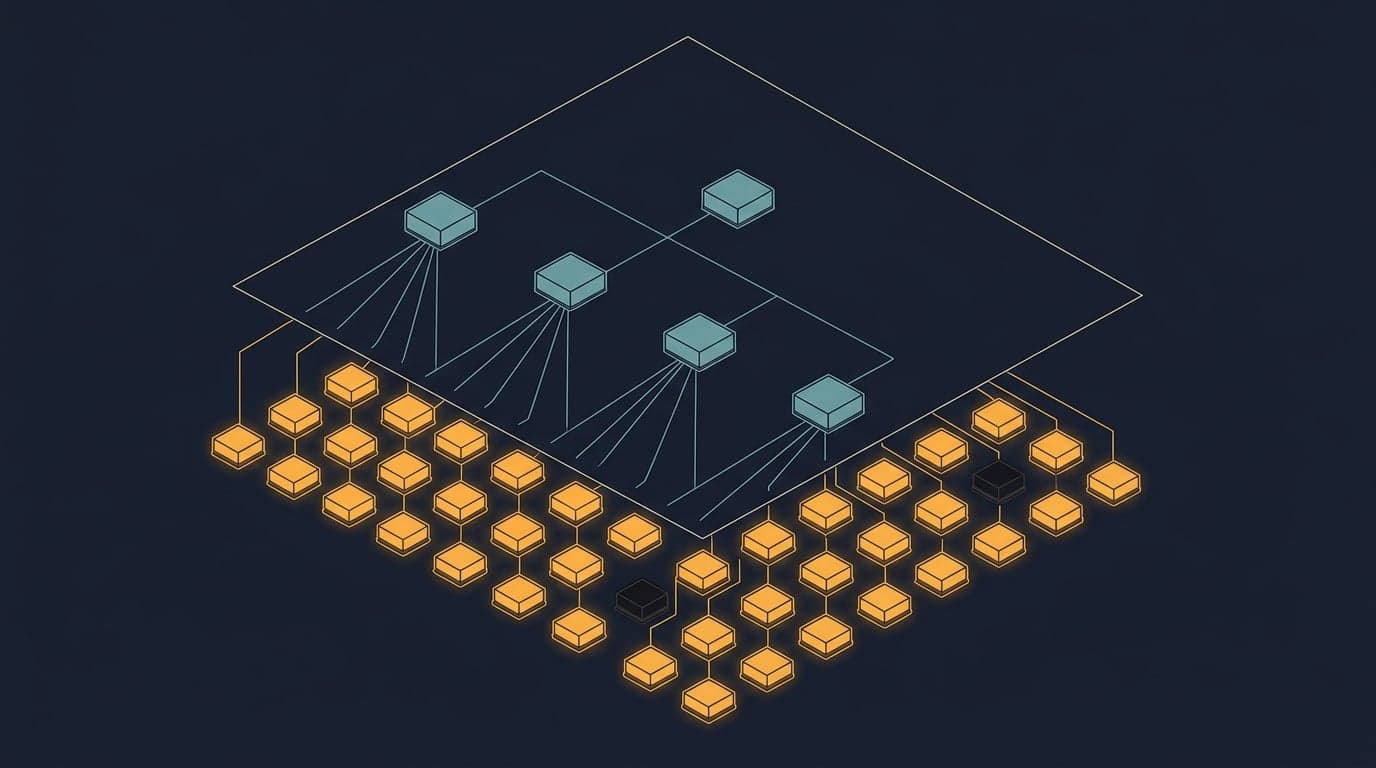
Workers and Observers: The Topology That Makes Fault Tolerance Structural
Share-nothing processes give you isolation. What turns isolation into recovery is the supervision tree.
Armstrong describes the pattern directly: worker processes perform computation, observer processes watch the workers and perform error recovery when something goes wrong. This isn't just a library feature bolted onto the language — it's the intended architecture. The system is designed so that failure is a normal event with a defined response, not an exceptional condition that propagates upward until something catches it.
The BEAM There, Done That podcast episode with Ellyse Sedeno makes this concrete in a domain far from telecom. Sedeno, who works at the intersection of distributed systems and game backends, describes a multiplayer game server architecture where each player and each mob runs as its own supervised process. Movement events arrive in a mailbox and are processed without locks. When the world server crashes, it restarts under supervision without affecting the chat server. The failure modes are visible, bounded, and recoverable — rather than total.
Her observation about the call vs cast distinction is worth pausing on. Synchronous calls between actor processes can create circular dependencies — the actor model's structural equivalent of a threading deadlock. The difference is that in a process topology, these dependency cycles are visible in the architecture before they become runtime disasters. You can reason about them structurally in a way that's nearly impossible with traditional thread-and-lock concurrency.
Distribution Falls Out of the Model Almost for Free
Here's the part that still surprises people: the same design that makes Erlang fault-tolerant also makes it distributable with minimal additional work.
Armstrong's paper notes that turning a non-distributed program into a distributed one can often be achieved by allocating parallel processes to different machines. Because processes already communicate only through message passing and share no memory, the question of whether two processes are on the same machine or different machines is largely a deployment detail rather than an architectural one.
This is not magic — distributed systems have their own failure modes that don't disappear just because your concurrency model is clean. Network partitions, message delays, and Byzantine behaviors are real. But Erlang's model means you're not also fighting the accidental complexity of shared-state concurrency on top of the inherent complexity of distribution.
Lucas Sifoni's exploration of sparse Erlang cluster topologies illustrates this in practice: an Erlang cluster can be fully meshed or sparsely connected, and the graph-traversal problem of mapping an arbitrary cluster from a single node is solvable by asking nodes for their neighbors — the same message-passing primitives that handle local concurrency extend naturally to distributed topology discovery.
The lesson isn't "use Erlang." It's that fault tolerance isn't a feature you add to a system — it's a consequence of how you model failure in the first place. When you design around the assumption that processes will crash, and build recovery into the topology rather than trying to prevent crashes through defensive programming, you get a system that heals. The AXD301's nine nines weren't achieved by writing perfect code. They were achieved by writing code that expected imperfection and planned for it structurally.
That's a design philosophy worth carrying into whatever runtime you're actually working in.


