Lesson 4 of the Language Archaeology curriculum
Here's a design constraint that most programmers never face: your software controls telephone switches. A single switch handles tens or hundreds of thousands of simultaneous calls. When it fails, newspapers write about it. You cannot take it offline to deploy a fix. And "just restart it" is not an answer, because the calls are live.
That was the problem Joe Armstrong and his colleagues at Ericsson's Computer Science Laboratory sat down to solve in 1986. As Armstrong later wrote in his history of Erlang, the goal was explicit: "to provide a better way of programming telephony applications." The result was a language whose core ideas — lightweight processes, message passing, and supervised failure — still solve problems that most mainstream languages handle poorly or not at all.
This lesson is about one concrete idea: what Erlang's process model actually is, why it works the way it does, and what it teaches you about designing systems that stay up.
The Problem: Concurrency Is Hard Because State Is Shared
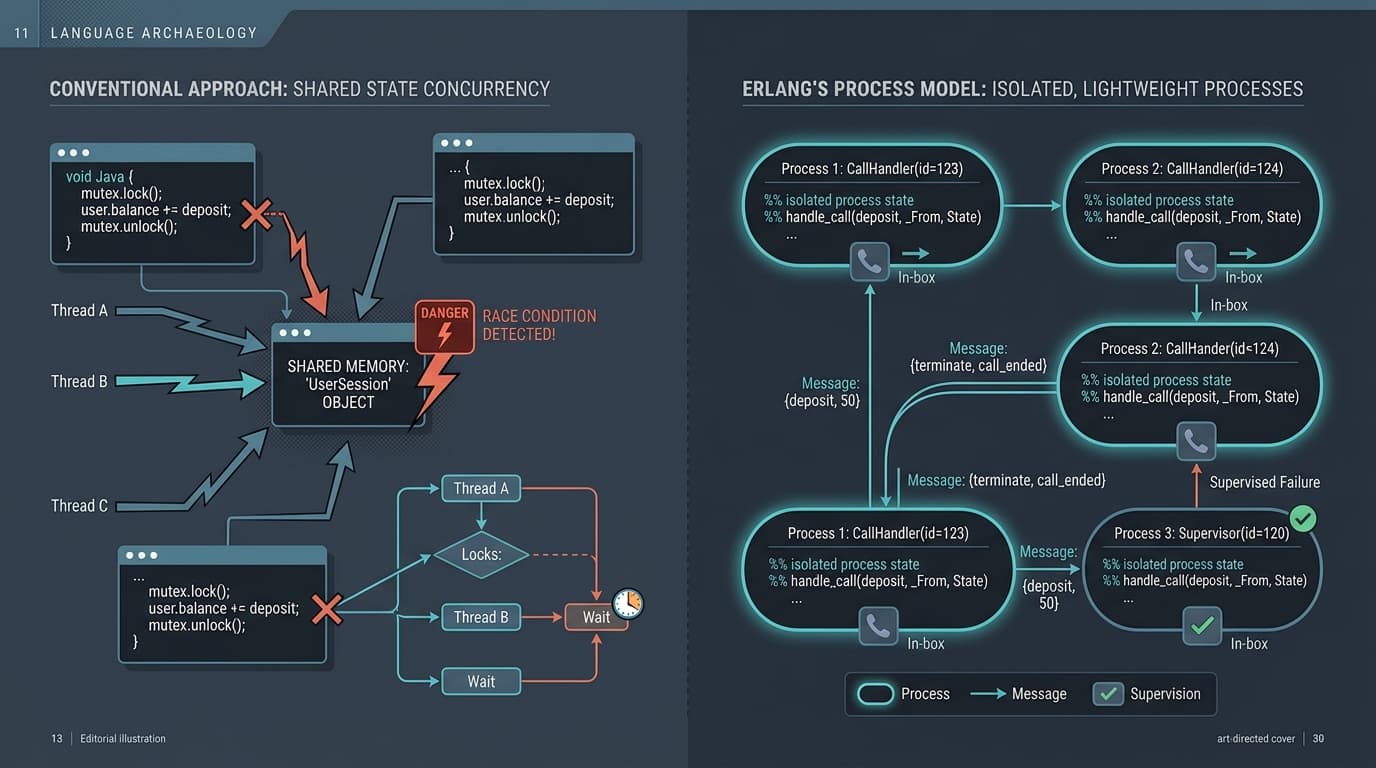
Most languages treat concurrency as a feature you bolt on. You have objects or functions, and then you add threads, locks, and mutexes to make them run in parallel. The result is a system where multiple threads of execution share memory — and where a bug in one thread can corrupt state that another thread depends on.
Erlang's designers rejected this approach at the foundation. According to the Erlang system documentation, the reason Erlang calls its execution units processes rather than threads is precise: "threads of execution in Erlang share no data with each other and the term 'thread' [is used] when they share data in some way."
No shared memory. That's the load-bearing wall of the entire design.
Each Erlang process is a completely isolated unit. It has its own heap, its own state, and the only way it communicates with any other process is by sending messages. You spawn a process with spawn, get back a process identifier (a pid), and send messages to that pid. The receiving process handles messages from its mailbox, one at a time, in the order they arrive.
spawn(tut14, say_something, [hello, 3])
That one line creates a new process. Not a thread sharing your heap. A separate, isolated worker with its own execution context. The documentation shows that when you spawn two processes that both print output, they interleave — hello, goodbye, hello, goodbye — because they genuinely run concurrently, each proceeding independently.
The practical consequence: a bug in one process cannot corrupt another process's state. It can only crash that process.
The Key Insight: Design for Failure, Not Against It
This is where Erlang's model becomes philosophically distinct from almost everything else.
Most languages — and most programmers — approach errors defensively. You write try/catch blocks. You validate inputs. You add null checks. The implicit assumption is that if you're careful enough, you can prevent failures from happening.
Armstrong's thesis, submitted to the Royal Institute of Technology in Stockholm in 2003, asked a different question: "How can we program systems which behave in a reasonable manner in the presence of software errors?" Not "how do we prevent errors" — how do we behave reasonably when they happen, because they will.
The answer Erlang gives is called "let it crash." As the Koder.ai analysis of Armstrong's work frames it: "don't over-defend every line of code; fail fast and recover cleanly using structure, not heroics."
The structure that makes this work is the supervision tree. Erlang processes can be linked to supervisor processes whose only job is to watch for crashes and respond — by restarting the failed process, restarting a group of related processes, or escalating the failure up the tree. You define the recovery policy in the supervisor, not scattered across your application logic.
This separation is the insight. Your business logic doesn't need to handle every possible failure mode. It just needs to do its job and crash cleanly if something goes wrong. The supervisor handles what happens next. The result is code that's simpler in each individual piece, and more resilient as a whole.
Why This Still Matters
Erlang processes are lightweight and belong to the language, not the operating system. That distinction matters enormously. OS threads are expensive — you can run thousands of them before hitting limits. Erlang processes are cheap enough that you can run hundreds of thousands on a single machine, each one representing a single user session, a single connection, a single unit of work.
This is the architecture that makes systems like chat servers, call routing platforms, and live notification systems tractable. Each connected user gets their own process. If one user's session crashes, it crashes alone. The supervisor restarts it. Every other user is unaffected.
I'd argue this is the model most modern distributed systems are groping toward — microservices, actor frameworks like Akka, even Go's goroutines all reflect some version of the same intuition. But they're often bolted onto languages that weren't designed around isolation from the start. Erlang built isolation into the runtime, the process model, and the standard library (OTP) simultaneously. Armstrong's thesis describes how some fault-tolerance requirements are satisfied in the language itself, and others in the standard libraries — the two were designed together, not assembled after the fact.
The other capability that falls out of this model almost for free: hot code loading. Because processes communicate only through messages and share no state, you can upgrade a module while the system is running. Old processes finish with the old code; new processes use the new code. The switch handles no downtime. Armstrong's history notes this was a hard requirement from the telecom domain — "without loss of service occurring in the application as code upgrade operations occur."
Your Next Action
The concept to sit with from this lesson is process isolation as a design primitive — not a performance optimization, not a concurrency trick, but the foundational unit of fault containment.
Before the next issue: take one system you work on and ask where its failure boundaries actually are. If one component crashes, what else goes down with it? Is that by design, or by accident? Sketch the answer. You don't need Erlang to think this way — but understanding why Erlang made isolation non-negotiable will sharpen the question considerably.


