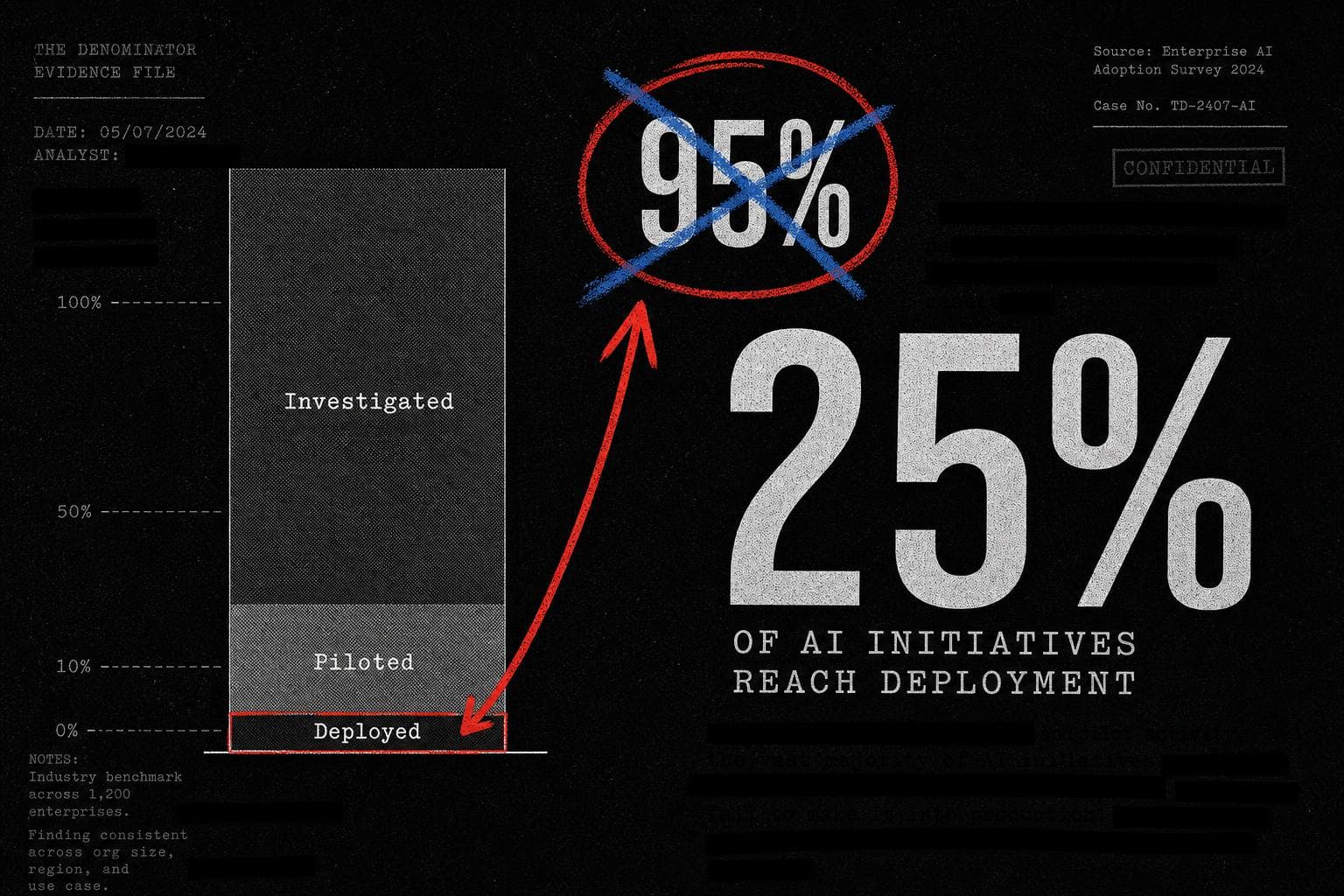
The Headline Number
"95% of generative AI pilots at companies are failing."
— Circulating widely in August 2025, repeated by Forbes, Axios, The Hill, and Harvard Business Review, attributed to an MIT study. Still being cited in 2026 as evidence that AI is overhyped.
The Audit
Let me show you the trick, because it's a clean one.
The study in question surveyed organizations about their experience with custom enterprise AI tools. Here's what it actually found, per a detailed breakdown of the original report:
- 60% of organizations had investigated custom AI tools
- 20% had piloted them
- 5% of the total had successfully deployed them in production
That 5% figure is real. The "95% failure rate" is not. It was constructed by treating the 5% deployment rate as evidence that 95% of pilots failed — which requires you to count organizations that never ran a pilot as failed pilots.
The analogy that cuts cleanest: it's like calculating that 95% of Tinder users have failing marriages, when 80% of your sample has never been on a date.
This is a denominator error, but it's a specific and particularly aggressive species of one. The base rate wasn't just wrong — it was fabricated by collapsing three distinct populations (investigators, pilots, deployers) into one, then treating the smallest group's share of the total as the failure rate for the middle group. That's not rounding. That's a different calculation entirely.
What the data actually showed about pilots: Among the 20% of organizations that did run a pilot, roughly 25% successfully deployed. That's a one-in-four success rate for early-stage enterprise technology adoption — which, if you've watched any enterprise software rollout in your life, is not a disaster. It's roughly what you'd expect.
There's a second problem buried in the methodology. The bar to count as a "success" in this study was full production deployment of a custom, task-specific AI tool. Not "useful." Not "cost-saving." Not "still running." Full deployment. The primary reason pilots didn't reach that bar, according to the survey's own data, wasn't technical failure — it was organizational resistance to adopting new tools. That's a change management problem, not an AI problem. Calling it a "failure rate" smuggles a causal claim into what is actually a description of corporate inertia.
And yet the report itself described its own graph as showing a "95% failure rate for enterprise AI solutions." The journalists who ran with the headline weren't entirely making things up — they were faithfully transcribing a number the report had already gotten wrong about itself.
This is how the most durable misinformation works. It doesn't require fabrication at the media level. It requires one bad methodological choice upstream, a number that sounds authoritative, and an ecosystem of outlets with no incentive to check the denominator. The MIT association did the rest. Nobody fact-checks a number that confirms what they already suspect.
The stat became a staple of the "AI is overhyped" discourse — cited in board presentations, investor memos, and congressional testimony — because it arrived pre-packaged with an elite institutional imprimatur and a conclusion that felt intuitively right. Feeling right is the enemy of checking the math.
Verdict: Misleading. The 95% figure misrepresents the study's own findings. The actual pilot success rate, using the study's own data, is approximately 25% — five times higher than what was reported, and not obviously bad for early-stage enterprise adoption.
By the Numbers
10.93% — The share of women prescribed mifepristone who, according to an Ethics and Public Policy Center report, experienced serious adverse events within 45 days. Republican lawmakers cited this figure repeatedly during Supreme Court arguments over mail access to the drug. A May 6 amicus brief from 360 reproductive health researchers called the EPPC report "riddled with methodological flaws," noting it was not peer-reviewed, drew on an undisclosed insurance claims database, and counted adverse events that occurred after drug use without establishing causation — the reframe being that an adverse event following mifepristone use is not the same as an adverse event caused by it.
2 of 5 — The number of recent presidential elections in which Justice Alito's majority opinion claimed Black voter turnout exceeded white voter turnout in Louisiana, cited as evidence that the Voting Rights Act's protections are no longer necessary. A Guardian analysis found the figure relies on measuring turnout as a share of the total over-18 population — which includes non-citizens and people with felony convictions who cannot legally vote — rather than the citizen voting-age population preferred by election researchers; using the standard methodology, Black turnout exceeded white turnout in only one of those five elections.
159 — The number of cruise-linked hantavirus cases that viral social media posts claimed the WHO had confirmed in early May 2026. Reuters found the WHO made no such confirmation; the posts were fabricated, a reminder that not every viral health statistic has a denominator problem — sometimes there's no numerator either.


