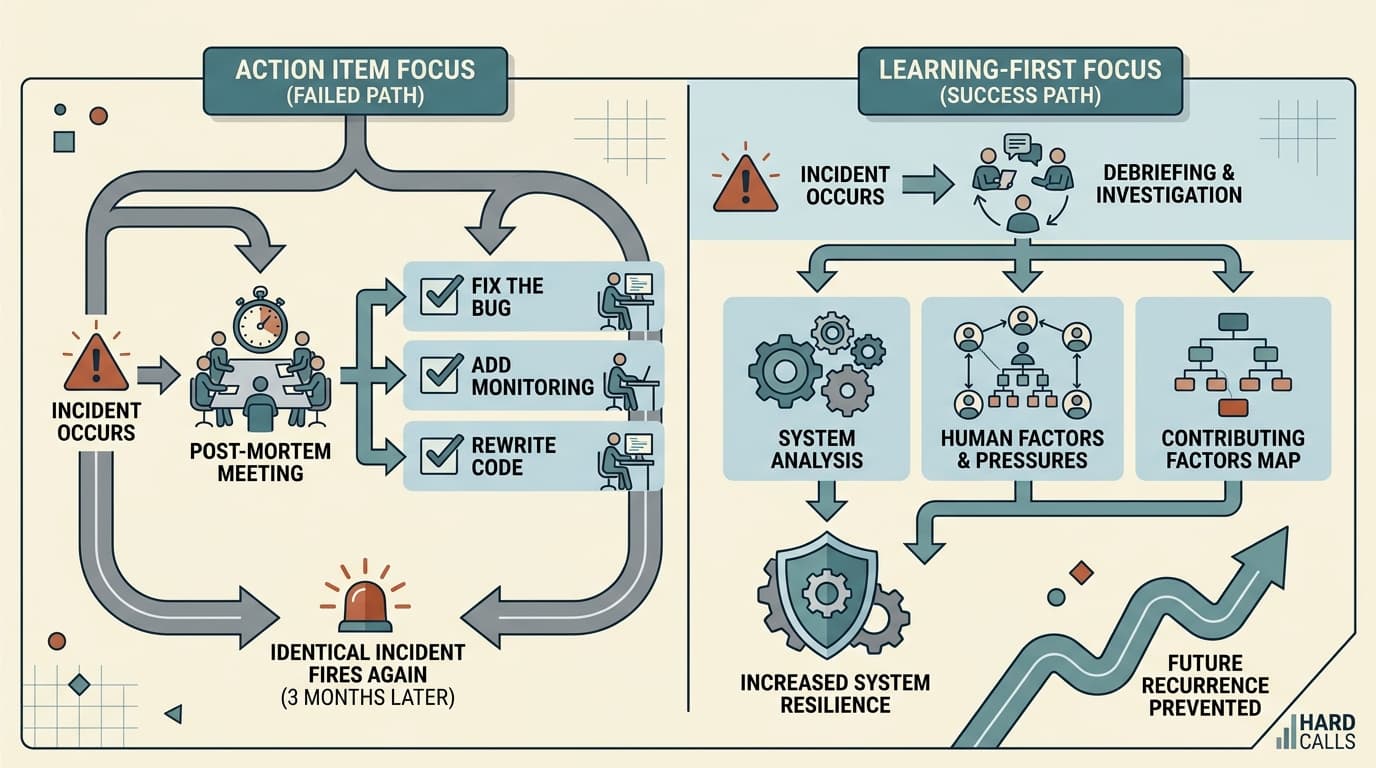
The incident is resolved. The timeline is documented. Someone's written up five action items and assigned them to engineers who are already behind on sprint work. Everyone files out of the meeting feeling like they did the responsible thing.
Three months later, a nearly identical incident fires. The action items are still open.
This is the most common failure mode in incident reviews — not that teams skip them, but that they confuse documentation with learning. The post-mortem exists, the artifact is real, and nothing actually changes. If you're running reviews that feel productive but aren't preventing recurrence, the problem usually isn't effort. It's what you're optimizing for.
You're Fixing the Incident, Not the System
Most post-mortems are implicitly organized around a question: what broke, and how do we fix that specific thing? That framing produces action items like "add a circuit breaker to the payment service" or "increase timeout thresholds on the auth layer." Useful, maybe. But narrow.
The more productive question is: what does this incident reveal about how our system — technical and human — actually behaves under pressure? That's a different investigation.
Etsy's debriefing facilitation guide makes this distinction explicit: a post-mortem should be considered first and foremost a learning opportunity, not a fixing one. When teams walk in with a story they've already rationalized, they're pattern-matching to a resolution rather than genuinely interrogating what happened. The timeline becomes a narrative that confirms what everyone already suspects, and the action items address the surface symptom rather than the underlying condition.
The fix for this isn't a better template. It's a different set of questions in the room.
Blameless Doesn't Mean Toothless
"Blameless culture" has become something of a management incantation — repeated often enough that it's lost meaning. What it actually requires is harder than it sounds: you have to resist the pull toward individual attribution even when individual decisions clearly contributed to the incident.
The reason isn't to protect engineers from accountability. It's that blame-focused reviews produce the wrong outputs. As incident.io's incident management guide notes, when post-mortems become blame sessions, engineers start hiding mistakes — working around issues instead of reporting them, building silos instead of sharing knowledge. Small problems compound into catastrophic failures.
The blameless post-mortem framework reframes the investigation: instead of "engineer X should have known about connection pooling," the question becomes "why didn't the system make the right behavior the default?" That shift — from person to system — is what produces fixes that actually hold. A template with pooling included by default, a linter check, updated onboarding docs. None of those require the engineer to be smarter next time.
The Five Whys technique is useful here, but only if you keep going past the first human decision point. Most teams stop when they hit a person. The productive version keeps asking why until you reach something structural — a missing check, a gap in documentation, a monitoring blind spot, a process that assumed knowledge engineers didn't have.
Action Items Are Where Reviews Go to Die
Even teams running genuinely good reviews tend to fumble the follow-through. Action items get written, assigned, and then quietly deprioritized when sprint planning happens and the incident is no longer fresh.
Two things make the difference. First, action items need to be specific and measurable — not "improve monitoring" but "add an alert for connection pool exhaustion on the auth service, owned by [name], done by [date]." Vague action items are a way of feeling like you've addressed something without actually committing to it.
Second, they need to live somewhere that gets reviewed. A structured post-mortem process puts action items into the sprint backlog, not a separate tracker that nobody opens. If the work isn't competing for real prioritization alongside feature work, it's not real work — it's theater.
The signal that your reviews are working isn't that action items get completed (though they should). It's that the same class of incident stops recurring. If you're seeing variations on the same failure pattern every few months, your reviews are producing documentation, not learning.
Three Questions to Ask Before You Close the Review
What would have had to be true for this not to happen? Not "what should the engineer have done differently" — what would the system, the process, or the tooling have needed to look like? That's where your real action items live.
Are the action items specific enough that someone could verify they're done? If the answer requires judgment ("is the monitoring better?"), rewrite it until it doesn't.
What's the next incident that this failure mode makes more likely? Incidents rarely travel alone. The conditions that produced this one usually exist in adjacent systems. The review isn't finished until you've asked what else is fragile in the same way.


