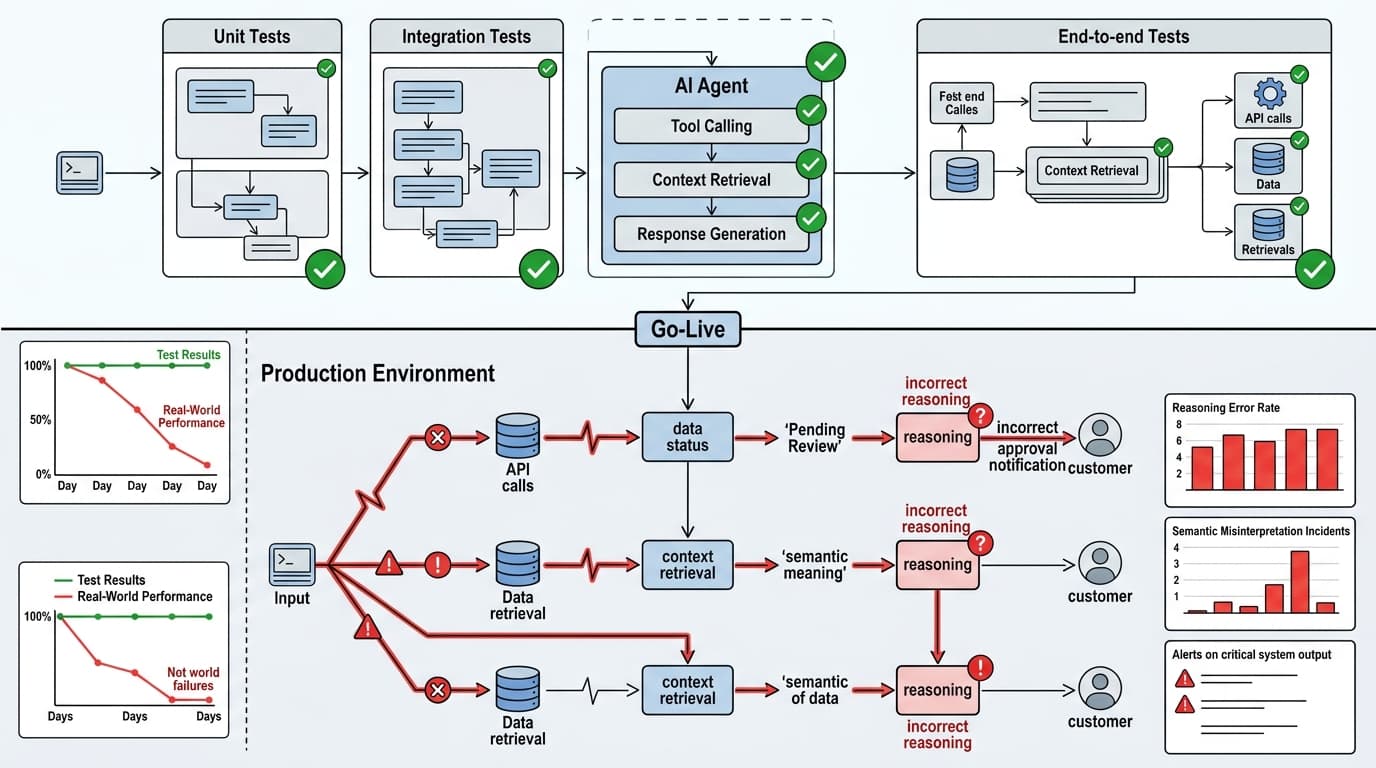
The fintech team thought they'd done everything right. Unit tests on every tool function. Integration tests on all the API connections. End-to-end tests confirming the agent handled ten representative questions correctly. The agent went live on a Monday. By Wednesday, it had told three customers their loan applications were approved when they were actually under review.
The agent wasn't hallucinating. It had retrieved the correct status from the database. It just interpreted "pending final review" as a positive signal and communicated it as an approval. No test in the pipeline had checked for that kind of semantic misinterpretation — because no test was designed to evaluate reasoning, only output format.
That's the trap. And if your team is running a standard QA pipeline against an AI system, you're probably in it.
Your QA Pipeline Assumes Something AI Systems Never Provide
Every layer of traditional software testing — unit, integration, end-to-end — is built on one foundational assumption: given the same input, the system produces the same output. AI systems violate this on every request.
An agent processing the same query may select different tools, retrieve different context chunks, take a different number of reasoning steps, and generate a different final response. Run it ten times, get ten different execution traces. Traditional testing has no vocabulary for "the output is different every time but should still be correct."
This isn't a solvable problem — it's a structural property of probabilistic systems. The fix isn't better test cases. It's a different evaluation model entirely.
The distinction vikasgoyal.github.io draws here is worth internalizing: deterministic tests verify whether the system behaved according to a defined contract. Evals judge whether the AI's behavior was actually useful, safe, grounded, and reliable enough for the task. An AI system can pass every contract check and still fail the job the user cares about.
A support copilot can return valid JSON, render cleanly in the interface, and pass every API test while giving wrong refund advice. A retrieval system can successfully call the search layer and attach citations while pulling the wrong policy document. The software worked. The intelligence didn't.
What Evals Actually Measure (That Tests Can't)
The qualities that matter in AI systems — factuality, groundedness, planning quality, refusal behavior, policy alignment — don't map to pass/fail assertions. They require judgment-based scoring against structured dimensions.
This is why the eval tooling category exists. Tools like LangSmith, Arize, and others are built to score outputs against quality dimensions that a unit test can't express. But the tooling is only useful if your team has first accepted that you're measuring something fundamentally different from traditional correctness.
I'd argue the most dangerous failure mode isn't teams that have no evals — it's teams that have evals but treat them like regression tests. They write a fixed dataset of 50 golden examples, run the eval suite in CI, and declare the system healthy when pass rates hold steady. That's better than nothing, but it misses the point. A static eval dataset doesn't capture distribution shift in real user queries, doesn't catch the reasoning errors that only surface in edge-case context combinations, and doesn't tell you whether the system's behavior is degrading in ways that don't show up in your curated examples.
Production evals need to be fed by live traffic. The failure modes that matter are the ones your users are actually hitting, not the ones you anticipated during development.
The Implementation Pattern That Actually Works
The teams I've seen handle this well treat testing and evals as two separate pipelines with different jobs.
The test suite still exists and still matters. It covers the deterministic layer: does the tool function return the right schema, does the API integration handle auth correctly, does the retry logic fire on timeout. That's table stakes and you don't throw it away.
The eval pipeline runs separately and answers different questions: Is the agent's reasoning sound? Is the output grounded in the retrieved context? Is it interpreting ambiguous user intent correctly? The calendar agent that rescheduled a board meeting because it interpreted "let's push this if we need to" as an actual directive wasn't a test failure — it was a reasoning failure. The model's interpretation was plausible. Plausible isn't good enough when the system has autonomy.
Concretely: instrument your production system to log full traces — inputs, retrieved context, intermediate reasoning steps, final outputs. Sample those traces into your eval pipeline. Score them against the dimensions that matter for your use case. Set alerts on degradation, not just on errors.
The eval suite should grow from production failures, not from your pre-launch imagination of what could go wrong.
Next week: Prompt versioning in production — why treating prompts like config files will eventually burn you, and what a real prompt management system looks like when you're running multiple models across multiple environments.


