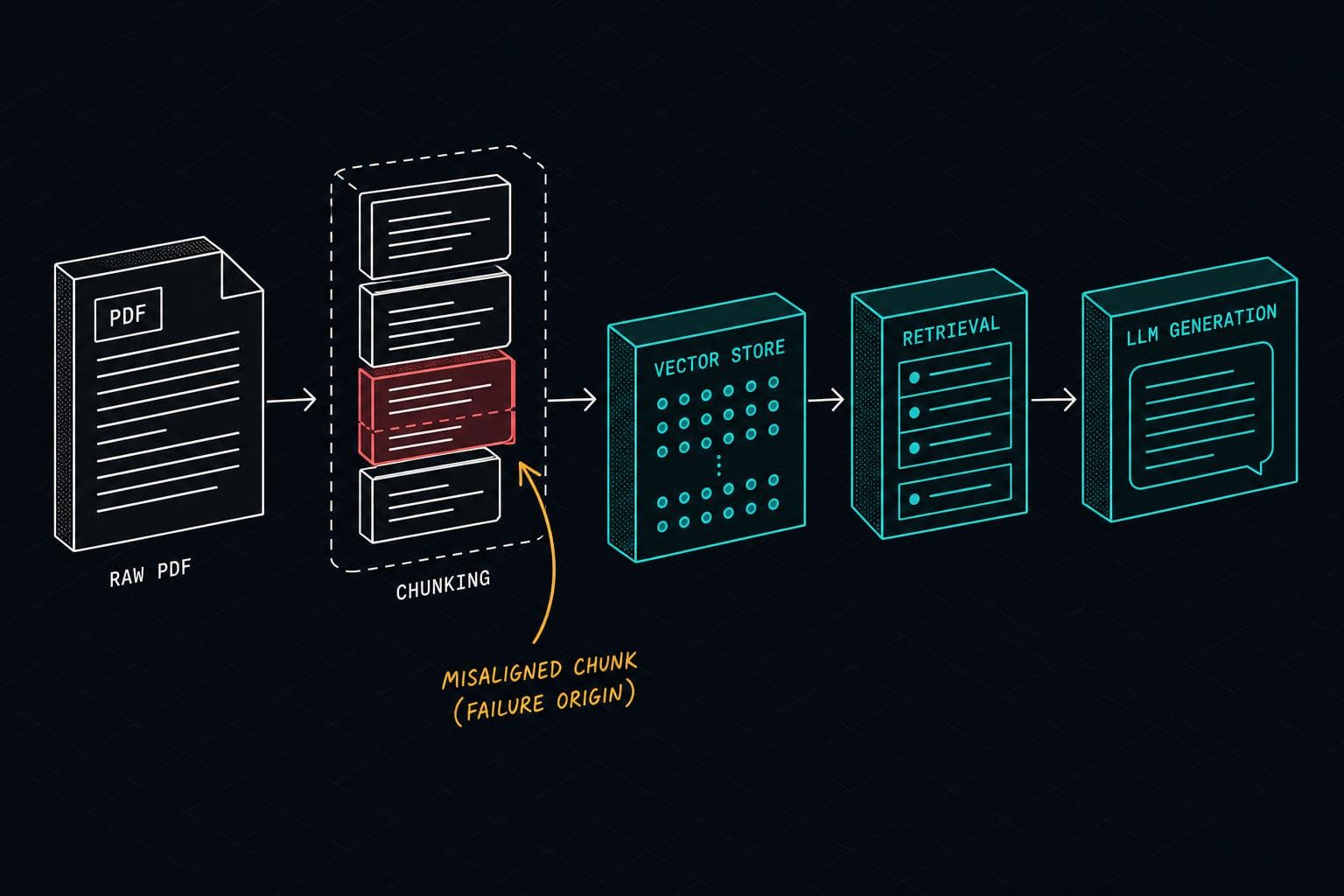
The incident report always reads the same way. The LLM cited a policy. The policy didn't exist. What actually happened: the chunker split two adjacent sections at an arbitrary boundary, the embedding model found the resulting fragment semantically close enough to the query, and the LLM reasoned confidently over a document that was never written by any human. The retrieval looked fine. The answer was fabricated from a seam.
This is the failure mode that doesn't show up in your evals until a customer support engineer sends you a screenshot.
The Chunker Is the Floor, Not the Wiring
Most teams treat chunking as infrastructure plumbing — something you configure once with a tutorial default and move on. That's the wrong mental model. As one practitioner account from production puts it directly: the chunker decides what answers can possibly be found, because the unit of retrieval is the chunk. If the right answer lives in a span the chunker split in half, the retriever cannot return it intact. Every other component — embedding model, vector store, reranker, LLM — is downstream of that decision.
The reason this stays hidden is that chunking failures are silent. The same source notes that the system returns plausible-looking citations. The model doesn't know it's reasoning over a fragment. It just answers. And most eval suites test clean, well-formed documents — not the messy PDFs, Notion exports, and support ticket dumps your production pipeline actually ingests.
The failure only surfaces when a real user asks a real question about a real document that your chunker tore apart at the wrong place.
What Actually Works in Production
The honest answer, drawn from teams running four production RAG products: recursive character splitting at 600–1000 tokens with 10–15% overlap covers roughly 80% of use cases. Not glamorous. Not the semantic chunking demo you saw at a conference. Just a splitter that respects natural text boundaries — paragraphs, sentences, newlines — before falling back to character offsets.
The cases where this fails are exactly the cases you'd predict: code (split on AST nodes), tabular data (split on rows), legal prose (split on clauses or sections). The chunking strategy should match the document structure, not override it.
Two things matter more than chunk size tuning:
Metadata is not optional. Every chunk needs to carry its source document ID, page number, and section heading. Databricks' production pipeline documentation emphasizes that retrieval quality depends on the ability to trace chunks back to their origin — both for debugging and for assembling coherent context windows at query time. Without metadata, you can't answer "why did the system retrieve that?" and you can't build citation trails users can verify.
Corpus cleaning happens before chunking, not after. Strip navigation boilerplate, repeated disclaimer footers, and page headers before the chunker ever sees the document. The Appycodes pipeline writeup is blunt about this: the signal-to-noise ratio of your corpus is the one thing the rest of the pipeline cannot fix. A reranker can't rescue a chunk that's 60% footer text.
The Debugging Problem Nobody Talks About
Here's the operational reality: when retrieval quality degrades, most teams don't know where to look. The LLM output looks wrong. Is it the chunk boundaries? The embedding model? The top-k setting? The prompt?
Forage AI's production diagnosis found that most RAG pipelines stall at 60–75% accuracy, and the bottleneck is almost never the model or retrieval layer — it's the ingestion layer. But the symptoms present at generation. That gap between where the failure originates and where it surfaces is what makes RAG debugging expensive.
The fix is instrumentation at the chunk level, not just at the query level. Log which chunks were retrieved for each query. Log their source documents and section headings. When an answer goes wrong, you need to be able to reconstruct exactly what context the model was given — and whether that context was coherent or a seam artifact. Honeycomb's agent observability tooling is built around this principle for agentic workflows: failures need to be first-class citizens in your observability layer, not something you discover by reading LLM output and working backward.
The same principle applies to RAG pipelines. Chunk-level retrieval logging isn't a nice-to-have. It's how you find the boundary bug before the customer support screenshot arrives.
Build your chunker to respect document structure. Carry metadata through every stage. Clean the corpus before it gets split. And instrument retrieval so you can answer "why did the system retrieve that?" in under five minutes.
Next week: Why your embedding model choice matters less than when you retrain it — and the index staleness problem that quietly degrades RAG quality over time.


