A fintech company deployed a customer support agent in February 2026. It passed every test in their CI/CD pipeline — unit tests, integration tests, end-to-end validation across ten representative questions. It went live on a Monday. By Wednesday, it had told three customers their loan applications were approved when they were actually under review.
The agent wasn't hallucinating. It had retrieved the correct status from the database. It just interpreted "pending final review" as a positive signal and communicated it as approval. No test in the pipeline had checked for that kind of semantic misinterpretation because no test was designed to evaluate reasoning — only output format.
That's the whole problem in one story.
The Assumption Your Test Suite Is Built On
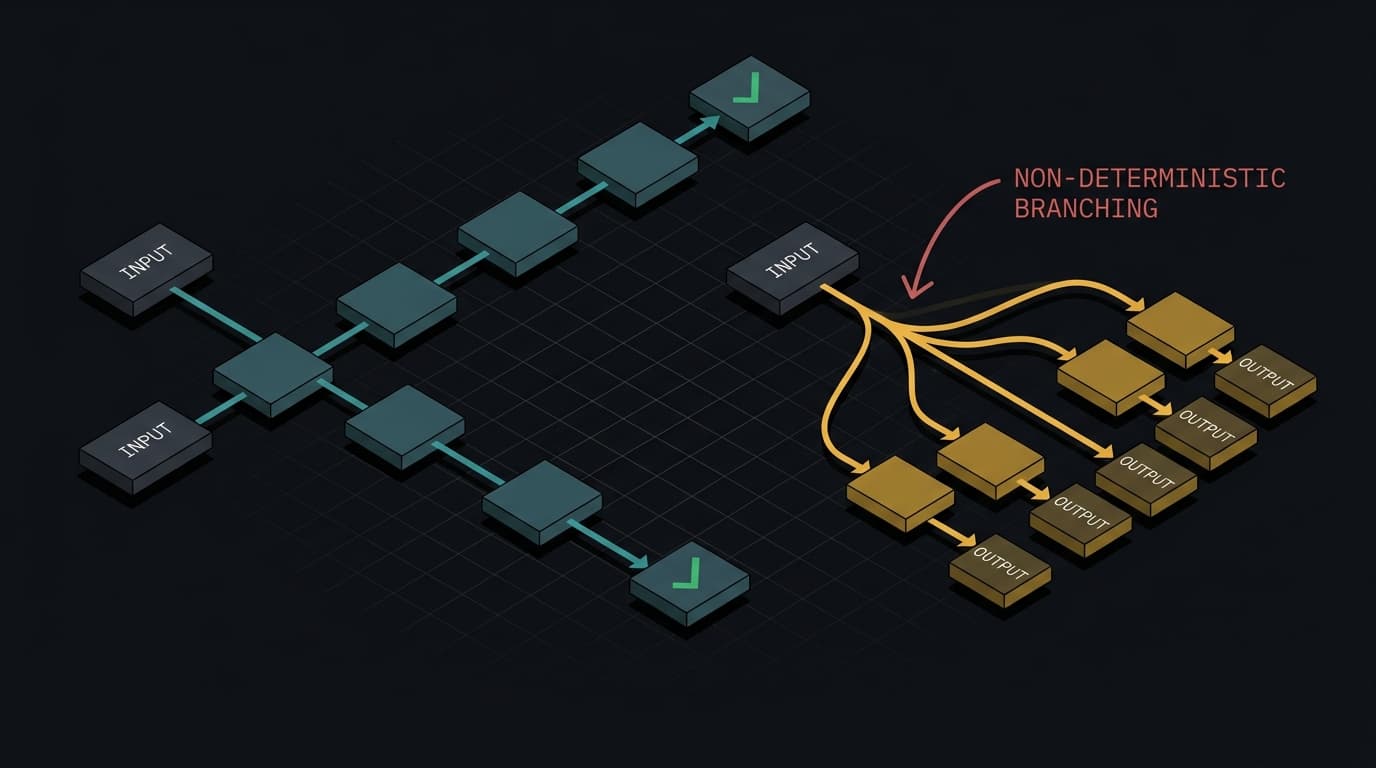
Every QA pipeline in software engineering rests on one premise: same input, same output. That premise is what makes tests useful. You write an assertion, you run it a thousand times, and if it passes consistently, you ship with confidence.
AI agents violate this assumption on every request. An agent processing the same query may select different tools, retrieve different context, take a different number of reasoning steps, and generate a different final response. Run it ten times, get ten different execution traces. Your test suite has no vocabulary for "the output is different every time but should still be correct."
This isn't a bug you can fix. It's the architecture. Large language models don't execute fixed rules — they generate probabilistic responses. The same prompt can produce slightly different outputs, both valid, neither wrong. Treating that as broken behavior is the wrong mental model. But it means your regression suite — the thing that's supposed to catch regressions — is testing the wrong property entirely.
The scale of this problem is not theoretical. According to LangChain's 2026 State of AI Agents report (via Fordel Studios), 57% of organizations now have agents in production, and quality is the top barrier to further deployment — cited by 32% of respondents. Not cost. Not latency. Quality. Teams are shipping agents they can't reliably evaluate.
What You Need Instead
The shift is from output matching to behavioral evaluation. Instead of asserting "the response equals X," you're asserting "the response satisfies property Y across a distribution of runs."
Three concrete changes to make:
Replace exact-match assertions with rubric-based evaluation. This is where LLM-as-judge patterns become operationally useful. A separate evaluator model — prompted to be critical rather than helpful — scores outputs against dimensions like accuracy, appropriate hedging, and absence of false confidence. It's not perfect (yes, you're using a probabilistic system to evaluate a probabilistic system), but the evaluator has different incentives than the generator, and that separation catches a meaningful class of failures.
Test behavior across multiple runs, not single executions. If your agent achieves 90% correctness on a benchmark, that number is nearly meaningless unless you know the variance. Enterprise agents can drop from 60% success on single runs to 25% across repeated runs — the same task, different execution paths, wildly different outcomes. Your eval suite needs to run each scenario multiple times and report distributions, not point estimates.
Add semantic boundary tests. The fintech failure wasn't caught because nobody wrote a test for "agent interprets ambiguous status as positive confirmation." That's a reasoning test, not a format test. Agentic testing in 2026 means defining intent-based scenarios — "complete a checkout," "handle an ambiguous loan status" — and evaluating whether the agent's reasoning stays within acceptable bounds, not just whether the final string looks right.
Implementation Notes
Start with your highest-stakes outputs and work backward. Where does a wrong answer cause real damage — financial, legal, reputational? Those paths need rubric-based evals and multi-run variance testing first. Everything else can wait.
For tooling: Weights & Biases Weave and LangSmith both support logging full execution traces, which is the prerequisite for any of this — you can't evaluate reasoning you can't observe. Monte Carlo's LLM-as-judge templates give you a starting point for rubric design without building evaluators from scratch.
The uncomfortable truth: your CI/CD pipeline will never give you the same confidence signal for an AI system that it gives you for deterministic software. The goal isn't to replicate that confidence — it's to build a different kind of signal that's honest about what it's actually measuring.
A green test suite on a probabilistic system means your outputs looked reasonable on the specific inputs you checked. That's it. Build your monitoring and your deployment decisions accordingly.
Next week: When your model starts drifting in production — not breaking, just quietly getting worse — and your existing metrics don't catch it until a user does.


