That's not a hypothetical. It's the default outcome when teams treat model quality like uptime — something you check when users complain.
The problem is structural. Traditional observability tells you when your system is down. Model quality degradation is different: the system stays up, requests succeed, latency looks fine. What changes is whether the outputs are actually good. And that's invisible to your existing monitoring stack unless you've built something specifically to catch it.
Here's what makes this hard, and what actually works.
Why Your Current Monitoring Won't Catch It
When you ship traditional software, a broken function throws an exception. When a model starts degrading, it just... answers differently. Confidently. With no stack trace.
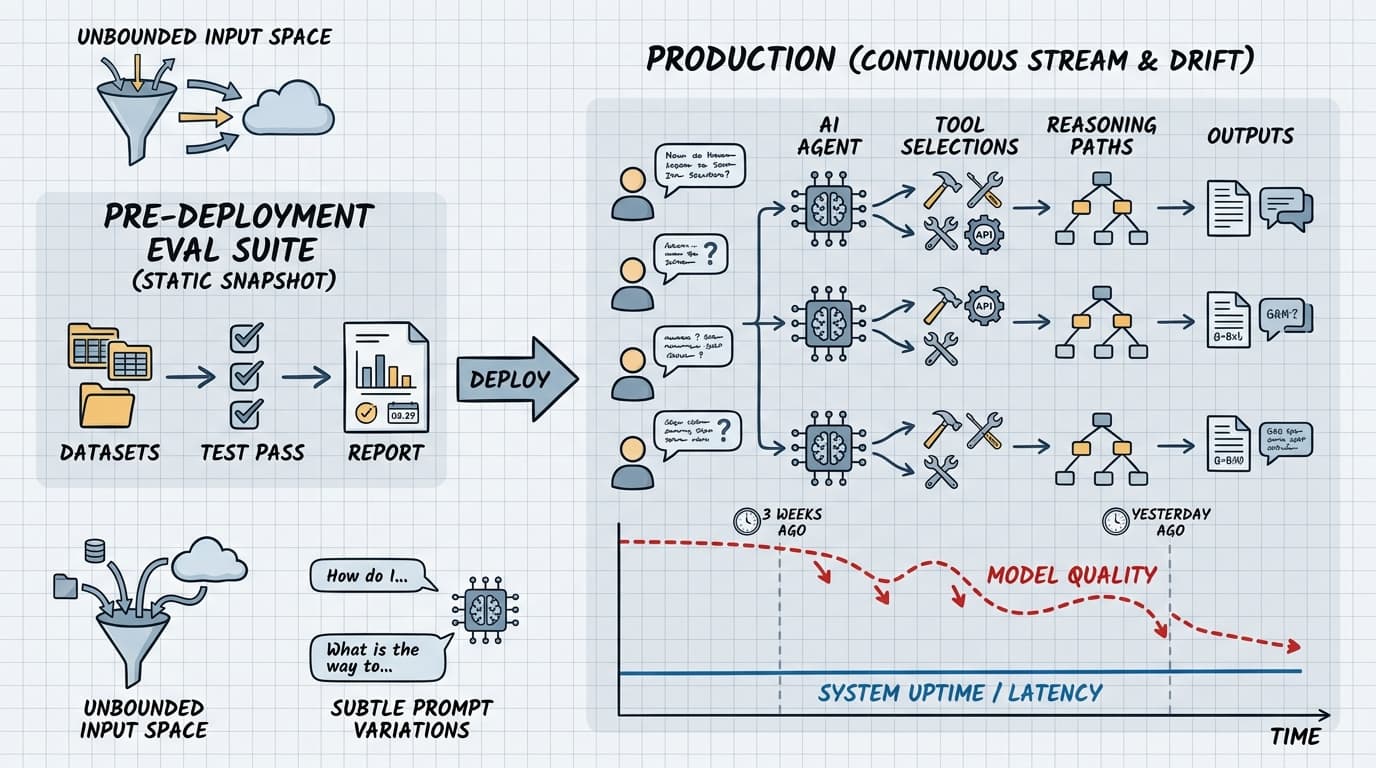
LangChain's engineering team frames the core problem well: agents accept natural language input with an unbounded input space, and they're sensitive to subtle prompt variations in ways that are nearly impossible to anticipate during development. The same user query can produce different tool selections, reasoning paths, and outputs across multiple runs. A single test pass tells you what can happen, not what typically happens.
This means your pre-deployment eval suite — however thorough — is a snapshot. Production is a continuous stream of novel inputs, and quality lives in the conversations themselves.
Drift compounds this. An analysis of 300 LLM drift checks across six months of production data found that classification tasks drifted 31% of the time, reasoning tasks 28%. The mechanism isn't always a model update you triggered — providers silently update weights, context distributions shift, and fine-tuning changes degrade adjacent capabilities. GPT-3.5 showed first drift in roughly 12 days on average. You probably weren't checking on day 13.
The teams that catch this early aren't smarter. They've just stopped treating model quality as a deployment-time concern and started treating it as a runtime one.
The Detection Pattern That Works
The practical approach has two layers: embedding-based drift detection and task-specific quality scoring.
Embedding-based drift is your early warning system. Establish baseline outputs for a representative sample of your production queries. Weekly — or more frequently for high-stakes tasks — run those same inputs through your current model, embed both the baseline and current outputs, and measure cosine similarity. The drift analysis suggests alerting when similarity drops below 0.8. This catches silent weight updates and distribution shifts before users do.
Quality scoring is where you get specific. AWS's AgentCore Evaluations documentation describes the failure surface clearly: wrong tool calls, correct tool with incorrect parameters, accurate tool execution but bad synthesis into a final answer. Each step in an agent's reasoning chain is a separate failure mode. Your scoring needs to cover the whole chain, not just the final output.
The implementation looks like this:
# Simplified quality gate — run this against sampled production traces
def score_trace(trace: AgentTrace) -> QualityResult:
scores = {
"tool_selection": eval_tool_selection(trace),
"parameter_accuracy": eval_params(trace),
"response_faithfulness": eval_faithfulness(trace),
}
# Alert if any dimension drops below threshold
failing = [k for k, v in scores.items() if v < THRESHOLDS[k]]
return QualityResult(scores=scores, failing_dims=failing)
The key discipline: score each dimension separately. A system that scores "response quality" as a single number will miss tool selection failures that happen to produce plausible-sounding outputs. Those are the failures that are hardest to catch and most expensive when they reach users.
Closing the Loop Before It Becomes a Postmortem
Detection without response is just expensive logging. The operational pattern that matters is: detect → triage → act, with clear ownership at each step.
Triage means distinguishing between drift that's cosmetic (output format shifted, severity low) and drift that's functional (classification accuracy dropped, tool calls failing). The drift analysis found that reasoning tasks show medium-to-high severity drift — those warrant immediate response. Generation tasks tend toward low severity — you can schedule a review.
Response options, in order of cost: adjust your prompt to compensate for the drift, pin to a specific model version if your provider supports it, or rebuild your eval baseline around the new behavior if the change is actually an improvement. The third option sounds like giving up, but sometimes a provider update genuinely improves things in ways your old baseline penalizes.
The teams that handle this well treat their production traces as a continuous eval dataset. Every flagged trace is a candidate for your test suite. AWS's evaluation framing describes this as a continuous cycle: build test cases, run them, score results, analyze failures, implement improvements. The teams that skip the "analyze failures" step are the ones filing postmortems.
One number worth internalizing: Booking.com found that improving model accuracy often didn't improve business outcomes. The inverse is also true — model degradation doesn't always show up in your product metrics immediately. By the time it does, you've lost weeks of signal. Build the monitoring that catches it before your users become your detection system.
Next week: Prompt versioning in production — why treating prompts like config files is a trap, and what a real prompt change management process looks like.


