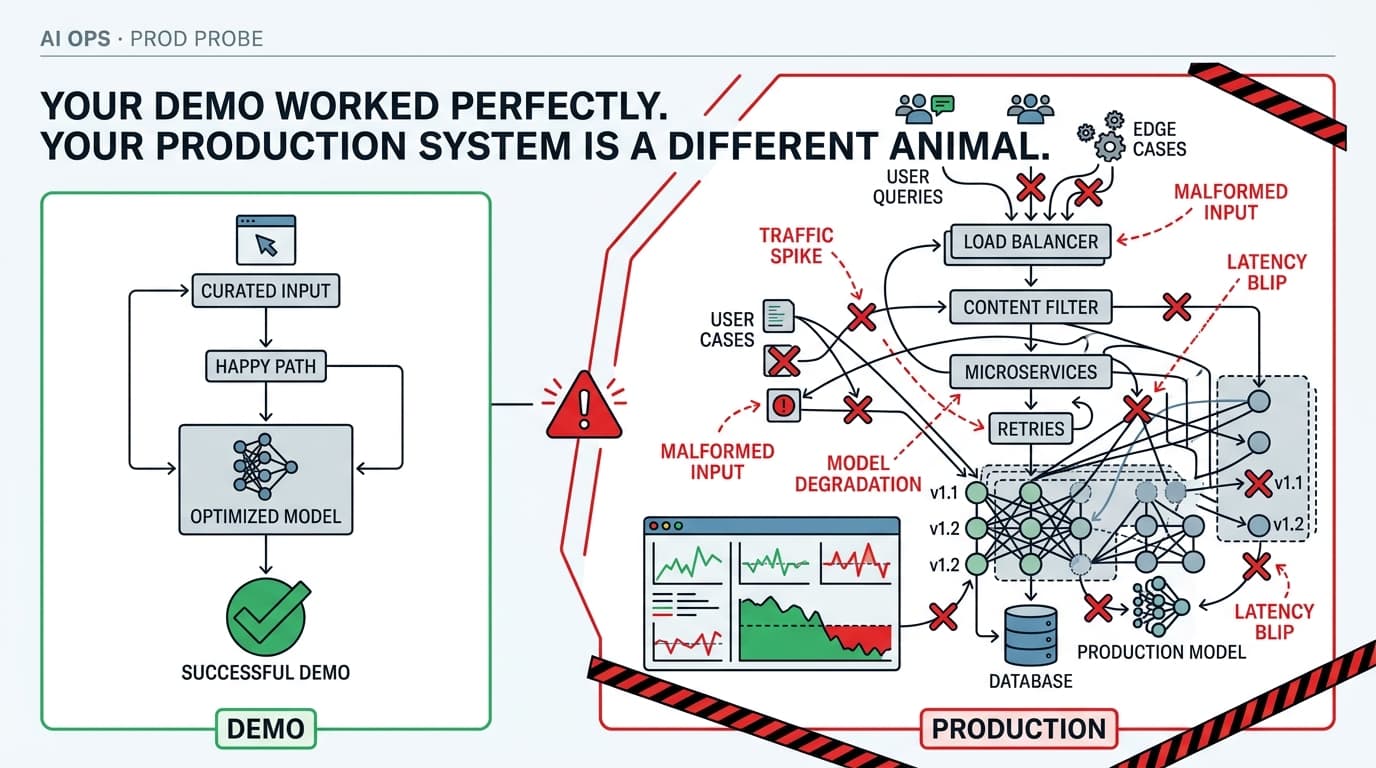
The demo crushed it. The founder showed the model handling edge cases, the latency looked snappy, the outputs were coherent. Everyone in the room was impressed. Six weeks later, the on-call engineer is getting paged at 2 AM because the feature is silently returning garbage — and nobody noticed for three days.
This is the gap nobody talks about at the conference. Not the gap between research and production (that one's well-documented), but the gap between demo-grade and production-grade reliability. They look identical until they don't.
The Demo Is an Optimized Path. Production Is Everything Else.
Here's what a demo optimizes for: a curated input, a single happy path, a human in the loop who can retry if something looks off. The model performs well because the conditions are controlled.
Production is the opposite. Real users send malformed inputs, edge-case queries, and prompts that hit content filters in ways you never anticipated. Traffic spikes at inconvenient times. The model provider has a bad afternoon. Your prompt that worked beautifully in March starts degrading in May because the underlying model was quietly updated.
The insidious part — and this is the thing that burns teams — is that AI systems fail softly. As ModelsLab's engineering blog puts it: "When your AI API integration degrades in production, it usually doesn't throw an exception. Latency creep, silent content filter rejections, subtle quality degradation — these require proper logging, sampling, and alerting to catch."
That's the core problem. Your error rate dashboard stays green while your product quietly gets worse. Users churn. Support tickets accumulate. And your postmortem, when it finally happens, is a probabilistic reconstruction rather than a clean root cause.
Root Cause Analysis Breaks Down When the System Is Probabilistic
Traditional SRE tooling assumes deterministic systems. A service either returns 200 or it doesn't. A database query either executes or it times out. You can replay the exact request and reproduce the failure.
LLMs don't work that way. The same prompt can produce meaningfully different outputs across calls. Model behavior can shift without a deployment event — provider-side updates, infrastructure changes, or simple temperature variance can all move your quality metrics without triggering any alert you've configured.
TFiR's reliability engineering coverage captures the resulting dysfunction well: teams "fall into the familiar loop: roll back, redeploy with more logging, redeploy again to confirm, and repeat until the picture is clear enough to act. Root cause analysis becomes probabilistic instead of proven. Fixes are deployed without runtime validation."
I've seen this pattern at teams that are otherwise operationally mature. They have great observability on their infrastructure layer. They have zero observability on their model behavior layer. So they're flying blind on the part of the system that's actually failing.
The Pattern That Actually Works: Treat Output Quality as a First-Class Signal
The fix isn't exotic. It's applying the same discipline to model outputs that you already apply to service health — but you have to instrument for it deliberately, because nothing will do it for you automatically.
Step one: Sample and log outputs, not just latency and error codes. You need a record of what the model actually said, not just whether it responded. This sounds obvious. Most teams don't do it because of cost and privacy concerns. Work through those constraints — a 5% sample with PII scrubbing is infinitely better than no sample.
Step two: Build lightweight output evaluators that run in your pipeline. These don't have to be sophisticated. A regex check for known failure patterns, a length sanity check, a secondary LLM call that scores the output on a simple rubric — any of these will catch the obvious degradation that currently goes undetected for days. Weights & Biases and Langfuse both have production tracing tooling built for exactly this layer.
Step three: Gate deployments on output quality, not just unit tests. This is where most teams have a gap. They run evals during development and then ship. What they need is a canary deployment pattern where a slice of real traffic goes to the new prompt or model version, output quality is measured against baseline, and promotion is automatic only if quality holds. Harness's deployment documentation covers the mechanics of canary rollouts well — the key is wiring your AI quality metrics into the promotion gate, not just your infrastructure health checks.
Here's a minimal version of an output evaluator you can drop into a Python pipeline:
def evaluate_output(prompt: str, response: str, min_length: int = 20) -> dict:
issues = []
if len(response.strip()) < min_length:
issues.append("response_too_short")
refusal_phrases = ["I cannot", "I'm unable to", "As an AI"]
if any(phrase in response for phrase in refusal_phrases):
issues.append("possible_refusal")
# Optional: secondary model scoring
# score = call_scoring_model(prompt, response)
return {
"passed": len(issues) == 0,
"issues": issues,
"response_length": len(response)
}
Crude, yes. But this running on 10% of your traffic, logging to your observability stack, and alerting when the passed rate drops below threshold — that's a system that would have caught the silent degradation before day three.
Continuous Training Doesn't Save You From Deployment Blindness
There's a tempting belief that if you have continuous training pipelines in place, you're covered. You're not. CT handles model drift over time by retraining on fresh data — and Madrigan's MLOps coverage is right that "once a model is in production, the work isn't over." But CT doesn't protect you from a bad prompt change you shipped on Tuesday, or a provider-side model update that shifted your output distribution overnight. Those require runtime monitoring, not training pipelines.
The two systems are complementary. CT keeps your model relevant over weeks and months. Runtime output evaluation keeps your product working today.
The Operational Discipline Is the Product
Here's the thing that took me too long to internalize: the reliability work is the AI feature. The model is a component. The logging, the evaluators, the canary gates, the alerting — that's the system. Teams that treat the model as the product and the operational layer as overhead will keep having 2 AM incidents with probabilistic postmortems.
The demo worked because someone controlled the conditions. Your job in production is to instrument the uncontrolled conditions until you can see them clearly enough to act.
Start with output sampling. Everything else follows from that.
Next Week: Prompt versioning in production — why treating prompts like code (with proper diffs, rollback, and staging environments) is the single highest-leverage reliability improvement most teams aren't doing.


