Ask a team how they're serving models in production and you'll learn more about their engineering culture in five minutes than in any architecture review. Not because there's one right answer — there isn't — but because the reasoning behind the choices (or the absence of reasoning) tells you exactly where they are.
The pattern shows up consistently across production deployments. Teams that are struggling aren't necessarily using worse tools. They're using tools they can't explain, can't monitor, and can't change without downtime.
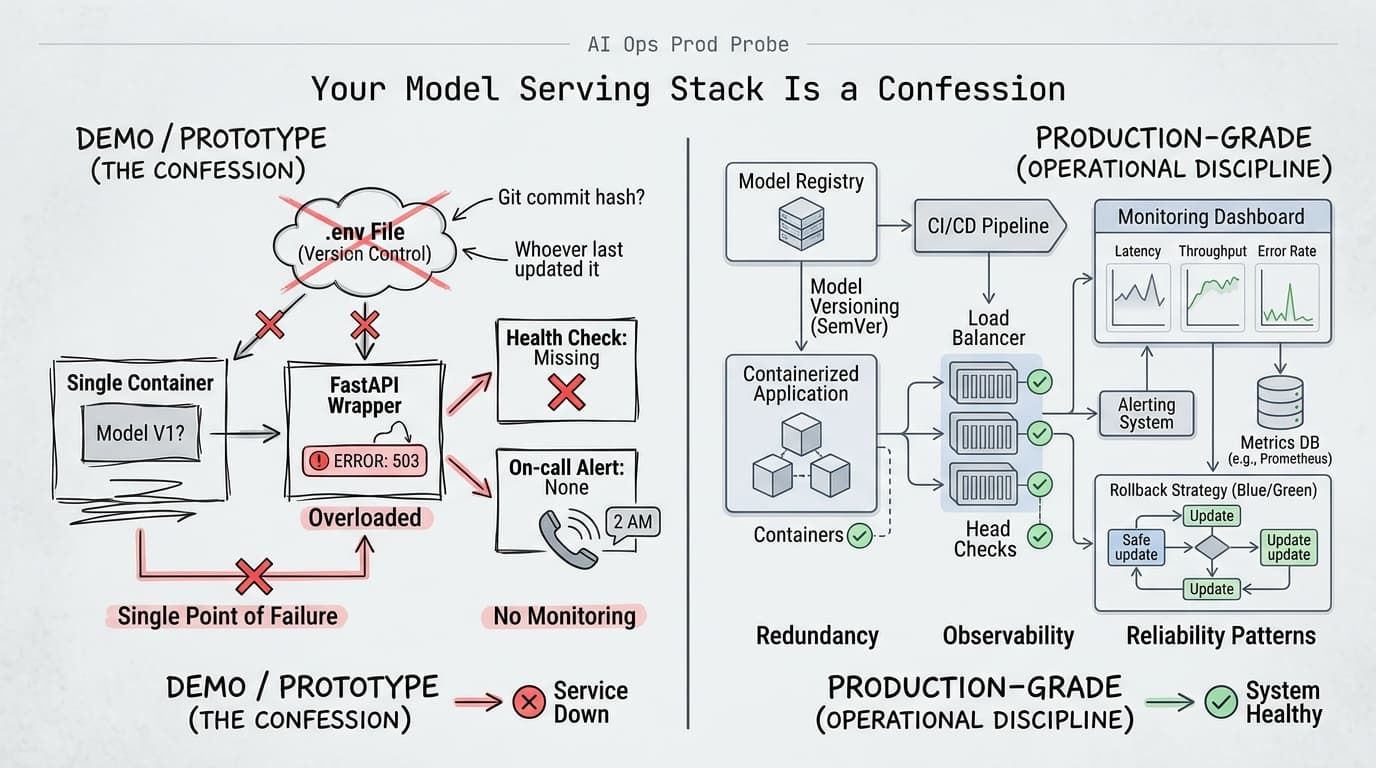
The Problem: Infrastructure Chosen for the Demo, Not the 2am Incident
Most teams pick their serving stack during the prototype phase, when the only requirement is "make it work." A FastAPI wrapper around an API call. A single container with no health checks. Model versioning handled by whoever last updated the .env file.
That's fine for a demo. It becomes a liability the moment you have real traffic, real users, and a real on-call rotation.
The ZenML analysis of 1,200 production deployments is blunt about what separates teams that shipped from teams that stalled: the shift from "interesting experiment" to production-grade system isn't a model problem, it's an engineering problem. The teams that made it rebuilt around operational requirements — reproducibility, observability, rollback — not around which model scored best on their eval set.
What usually goes wrong is predictable. Teams treat model serving like static software deployment. They don't track which model version is actually running. They have no clean path to update without downtime. GPU utilization is a mystery until something crashes. Monitoring, if it exists at all, is a latency graph that nobody looks at until users complain.
Don Simpson's write-up on serving sentence transformers at scale captures this exactly. His system was handling 1.7 billion records and worked fine locally. Moving to a long-lived service exposed every gap: no way to track which model version the API was serving, model updates required manual steps and downtime, GPU utilization was unpredictable, and there was no safe path for testing new models without risking the live system. The model was fine. The infrastructure was the problem.
What Mature Teams Do Differently
The infrastructure choices that signal maturity aren't exotic. They're boring in the best way.
Model versioning is non-negotiable. If you can't answer "what model is serving traffic right now, and what was serving it yesterday?" without checking Slack history, you don't have a production system. You have a prototype with users. Mature teams treat model artifacts the same way they treat application code — versioned, tagged, auditable. MLflow, DVC, or even a disciplined naming convention in object storage all work. The tool matters less than the discipline.
Zero-downtime deployments reveal whether you've thought about rollback. Rolling updates and blue/green deployments aren't just about uptime — they're about confidence. If deploying a new model requires taking the service down, you'll avoid deploying. That avoidance accumulates into technical debt: stale models, deferred fixes, and the eventual crisis when something breaks and you have no clean path back to a known-good state. Simpson's move to Kubernetes wasn't about scale — it was about getting rolling updates and safe model testing without disrupting live traffic.
Observability is where teams most visibly split. Immature teams monitor infrastructure: is the pod up, is latency under 500ms. Mature teams monitor model behavior: are embeddings drifting, are outputs changing in ways that correlate with user complaints, is GPU memory climbing in a way that predicts a crash before it happens? The Domino Data Lab maturity framework identifies this as a consistent inflection point — teams that instrument model-specific metrics (not just system metrics) are the ones that catch problems before users do.
The Pattern That Actually Works
The serving stack that holds up under operational pressure has three properties: it makes the current state visible, it makes changes safe, and it makes rollback fast.
In practice, that usually looks like this:
# Kubernetes deployment with explicit model version tracking
spec:
containers:
- name: model-server
image: your-registry/model-server:v1.4.2
env:
- name: MODEL_VERSION
value: "sentence-transformer-v3.1"
- name: MODEL_REGISTRY_URI
value: "mlflow://your-tracking-server/models/embeddings/3"
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
resources:
limits:
nvidia.com/gpu: 1
The model version is explicit in both the container tag and the environment. The readiness probe means Kubernetes won't route traffic until the model is actually loaded. The resource limit means GPU contention is bounded. None of this is clever — it's just the operational discipline that makes 2am survivable.
On the observability side, the minimum viable setup for a model serving endpoint is: request latency (p50/p95/p99), error rate by error type, and at least one model-specific metric — embedding cosine similarity distribution, output token length distribution, or whatever proxy tells you whether the model is behaving normally. Without that last piece, you're flying blind on the thing that actually matters.
Implementation Notes
A few things that don't get said enough:
Start with versioning before you start with monitoring. You can't debug a model behavior problem if you don't know which model is running. This sounds obvious and gets skipped constantly.
GPU serving requires explicit memory management. Unpredictable GPU utilization — the kind that requires periodic restarts — is almost always a model loading problem, not a hardware problem. Load the model once at startup, keep it resident, and instrument memory usage from day one. Surprises at 2am are almost always surprises that were visible in the metrics for days beforehand.
The cost argument for local inference is real. Simpson's move from API-based inference to local GPU serving dropped his costs to a few pounds per month for hardware and electricity. For teams running high-volume embedding or classification workloads, the break-even point on a GPU instance comes faster than most finance teams expect. Run the numbers before assuming API-based serving is cheaper at scale.
The ZenML deployment data makes one thing clear: the teams shipping reliable AI features aren't winning on model quality. They're winning because they treated the serving infrastructure as a first-class engineering problem from the start, not an afterthought they'd clean up later.
Your serving stack doesn't lie. Neither does your incident history.
Next week: Evaluation systems that don't require a data science PhD to maintain — what small teams are actually using to catch model regressions before users do.


