Most teams treat the local-vs-API decision as a one-time architecture call. Pick a side, commit, move on. That's the wrong frame — and it's why so many teams end up either hemorrhaging on API bills or drowning in infrastructure they didn't need.
The real question is: at what point does the math flip? And the answer changes depending on whether you're optimizing for latency, cost, or operational simplicity. You can't optimize all three simultaneously. That's not a design flaw — it's physics.
The Trilemma Is Real, and Most Teams Only See One Dimension
DigitalOcean's inference engineering blog frames this as a trilemma: throughput, latency, and cost pull in different directions, and improving one typically degrades another. Batch more requests to cut cost-per-token, and your P50 latency climbs. Optimize for time-to-first-token, and you're leaving throughput on the table.
Most small teams only track one of these dimensions — usually cost, because it shows up on a bill. Latency gets measured in vibes ("feels slow") until a user complains. Throughput gets ignored entirely until the system falls over.
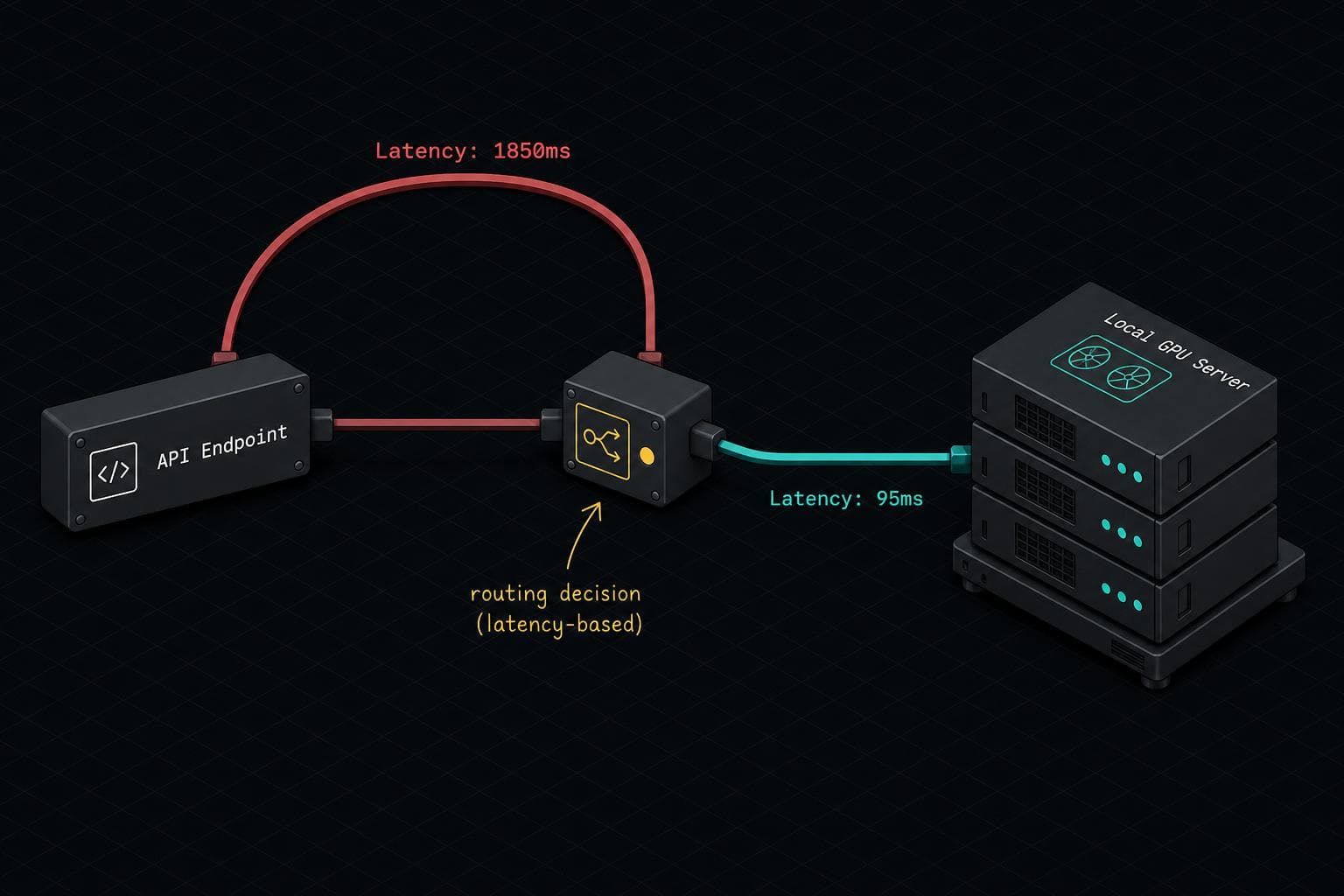
The operational trap: you make a routing decision based on cost data alone, then discover six months later that your P95 latency is 8 seconds on a user-facing feature. Now you're doing emergency architecture work under pressure.
Where the Math Actually Flips
A 30-day cost analysis from a team running autonomous agents at roughly 3,150 requests/month found that a local RTX 3060 Ti setup ran about $13/month all-in (hardware amortization plus electricity), while GPT-4o-mini on the same workload cost $1.32/month. At low volume, the API wins on cost — decisively.
But the same analysis documents what the pricing page doesn't: billing surprises from runaway agent loops, data residency constraints, and the latency floor imposed by a round-trip to a third-party endpoint. Those hidden costs don't show up until they bite you.
The build-vs-buy framework from Abstract Algorithms puts a harder number on the flip point: self-hosting becomes cost-effective above roughly 50M tokens/day with a dedicated MLOps team. Below that, you're paying engineering time to solve a spreadsheet problem. The post documents a startup that spent four weeks setting up vLLM for a workload that would have cost $90/month on GPT-4o — and ended up using the API anyway after the self-hosted model hallucinated on their domain-specific data.
I'd add a dimension that neither analysis fully captures: latency variance. Average latency is a vanity metric. What matters operationally is your P95 and P99 — the tail that determines whether your retry logic fires, whether your timeout thresholds hold, and whether your users notice.
The Serverless Middle Ground Has Real Spread
If you're not ready to self-host but the major API providers are too expensive or too slow, the serverless inference market for open-weight models is worth measuring. A Q2 2026 pricing matrix across seven providers — Together, Fireworks, Groq, Cerebras, Replicate, OctoAI, and Anyscale — shows pricing on the same model spreading 6× across the field, with P50 latency spreading 5–7×. Groq and Cerebras run 600–750 tokens/sec on 70B-class models using specialized hardware, at a 2–3× price premium over commodity H100 endpoints.
That spread matters. The wrong default isn't just a minor inefficiency — it's potentially 6× your token cost for equivalent quality. And the right choice depends on your workload shape: steady-state batch processing favors price-leaders like Together or Fireworks; streaming chat or real-time coding favors Groq or Cerebras; regulated industries with compliance requirements point toward Anyscale.
What to Actually Measure Before You Commit
The routing decision should be driven by instrumentation, not intuition. Before you lock in an architecture:
Measure your actual token distribution. Input-heavy workloads (long context, document analysis) price very differently than output-heavy ones (generation, summarization). Most teams estimate this wrong.
Run P50 and P95 latency under realistic concurrency. A provider that looks fast at one concurrent request may degrade badly at ten. Test at your expected peak, not your average.
Model your break-even on engineering time. Self-hosting isn't free infrastructure — it's infrastructure plus on-call burden plus upgrade cycles. If you don't have someone who wants to own that, factor in the cost of the person who will be paged at 2am when vLLM OOMs.
Build routing as a seam, not a hardcoded dependency. The team that can swap providers in a config change can respond to pricing shifts and model quality changes. The team that has the provider baked into ten call sites cannot.
The local-vs-API question isn't a one-time decision. It's a threshold you'll cross multiple times as your volume grows. The teams that instrument it properly are the ones who see the crossing coming instead of discovering it on their AWS bill.
Next week: What your error logs aren't telling you about model quality degradation — and the monitoring patterns that catch silent failures before users do.


