Most AI features don't stall because the model is wrong. They stall because the team around the model isn't set up to catch when it goes wrong.
I've watched this pattern repeat: a prototype impresses stakeholders, gets greenlit, and then spends three months in a holding pattern while the team argues about evaluation criteria, debugging tooling, and what "good enough" actually means in production. The model was fine from day one. The operational scaffolding was the bottleneck.
Datadog's State of AI Engineering report puts it plainly: "the gap between a good demo and a dependable system is closed by effective evaluation and operational discipline." Not better prompts. Not a smarter model. Discipline.
Here's what that discipline actually looks like.
Silent Failures Kill Shipped Features
The first thing teams get wrong is assuming their existing monitoring will catch AI problems. It won't.
A 2026 analysis of AI feature rollouts describes the failure mode precisely: when a fintech chatbot started dispensing outdated regulatory advice, every operational metric stayed green. Latency nominal. Error rates nominal. The canary looked healthy while the product was actively misleading users. The same piece cites an industry survey finding that 75% of businesses observed AI performance declines without proper monitoring, and over half reported revenue loss from AI errors that none of their existing dashboards caught.
This is the core problem. Traditional observability — 5xx rates, p99 latency, error budgets — grades deterministic systems. AI features fail in a completely different register. The output is structurally valid, the request completes successfully, and the answer is subtly, silently wrong.
Teams that ship AI features and keep them running have accepted this reality and built for it. They instrument at the output level, not just the infrastructure level. That means logging model responses, running automated quality checks against those responses, and treating quality degradation as a first-class alert condition — not something you discover in a user complaint six weeks later.
Monoliths Stall, Pipelines Ship
The second pattern that separates shipping teams from stalled ones is architectural. Teams that try to build AI features as a single, end-to-end prompt — one massive instruction, one model call, one output — end up with something that's nearly impossible to debug, evaluate, or improve incrementally.
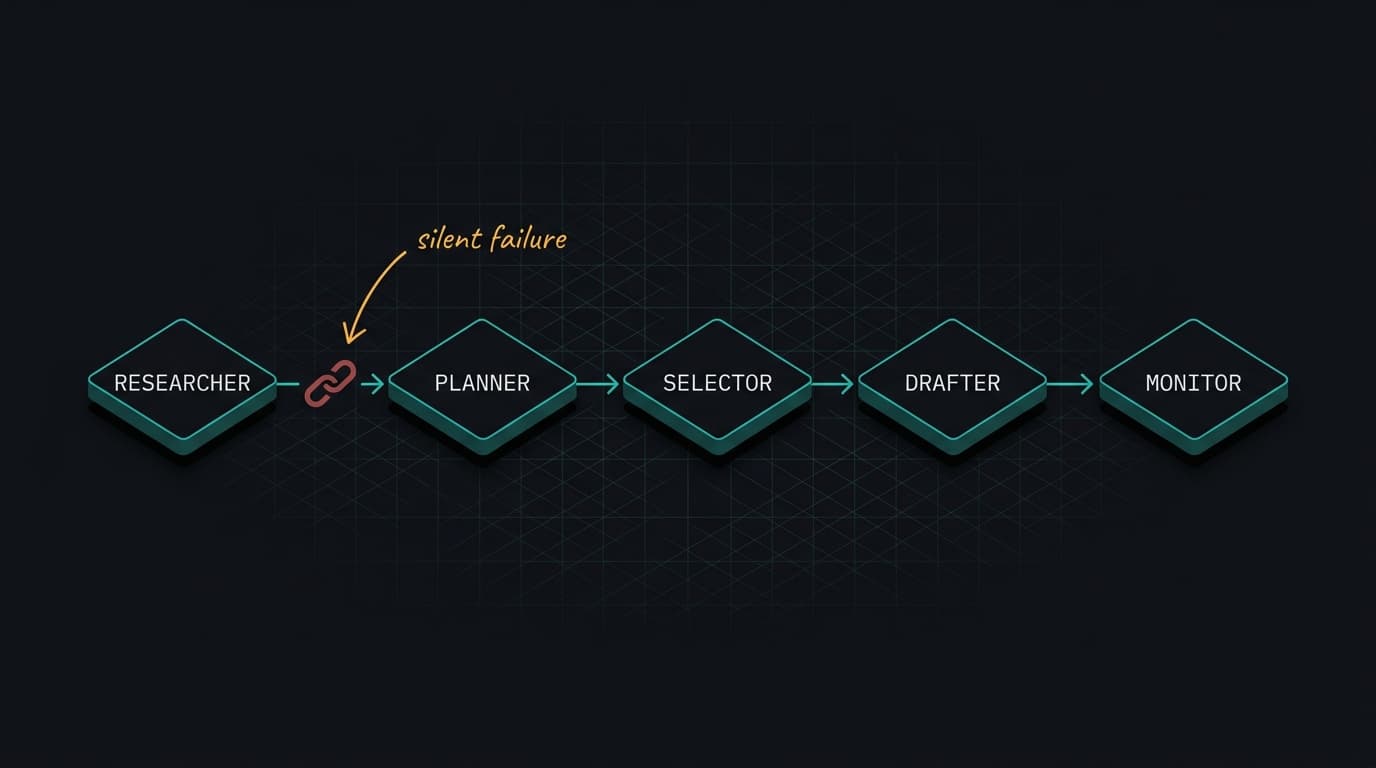
A Google Developers post on refactoring a production sales research agent documents this directly. The original agent ran on a monolithic Python script with a linear for loop. When any sub-task failed — an API timeout, a hallucination — the entire process stalled silently. The fix was decomposition: a SequentialAgent pipeline with specialized nodes for research, planning, selection, and drafting. Narrow tasks, explicit handoffs, observable state at each stage.
The operational benefit isn't just reliability. It's debuggability. When your AI feature is one giant prompt, you can't tell whether a bad output came from bad retrieval, bad reasoning, or bad formatting. When it's a pipeline, you can. You can also improve one stage without destabilizing the others — which is how you actually make progress after launch instead of being afraid to touch anything.
Structured outputs are part of this same discipline. The same Google post shows the before/after: prompt strings that describe JSON schemas in natural language versus Pydantic objects that enforce structure at runtime. The former produces brittle parsing and wasted tokens. The latter gives you a contract you can actually test against.
Evaluation Has to Come Before Deployment
The third pattern — and the one most teams skip because it's unglamorous — is having evaluation criteria defined before you ship, not after something breaks.
Weights & Biases frames this as the core MLOps gap: "Most AI investments don't underperform because the models are bad. They underperform because the infrastructure to support them was never built." The organizations running dozens of governed models in production aren't more talented. They invested earlier in the systems that make ML repeatable — version control for prompts and models, CI/CD pipelines that include quality checks, monitoring for drift.
For small teams, this doesn't have to be elaborate. It means: before you deploy, write down what "good" looks like for your specific feature. Build a test set of representative inputs with expected outputs. Run your model against that set on every prompt change. Track the scores over time. When scores drop, you have a signal before users do.
The Datadog report notes that model, prompt, or retrieval changes can move latency, spend, and failure rates without any obvious code change. If you don't have evaluation infrastructure, you're flying blind every time you touch the system — which means you'll eventually stop touching it, and the feature will quietly degrade.
The Operational Checklist That Actually Matters
If your AI feature is stalled, the bottleneck is almost certainly one of these three things: you don't have output-level monitoring that catches quality degradation, your architecture makes failures invisible and improvements risky, or you have no evaluation baseline to tell you whether a change made things better or worse.
Fix the monitoring first. You can't improve what you can't see. Then decompose the monolith so you can isolate failures. Then build the evaluation harness so you can ship changes with confidence instead of dread.
The model is probably fine. The question is whether your team can operate it.
Next Week: We're going into prompt versioning — specifically, why treating prompts like config files instead of code is the fastest way to lose track of what's actually running in production, and what a minimal but serious prompt management system looks like for a five-person team.


