The incident is always the same. Someone makes a small prompt edit — two lines, maybe a single character — and three days later you're manually tracing why a specific customer's outputs degraded. No diff to blame. No rollback path. Just a production system behaving differently than it did last week, and no infrastructure to tell you why.
One engineer documented exactly this after running AI agents in production for roughly six months: a single-character prompt change silently broke response quality for a specific customer's use case, and without per-response traceability, it took three days to find the cause. That's not a debugging failure. That's a missing infrastructure layer.
The pattern I keep seeing at small teams: prompt management starts as a non-problem and becomes a crisis somewhere between "we have one AI feature" and "we have six AI features and four people touching prompts."
The Failure Mode Is Invisible Until It Isn't
Here's what the early stage looks like. Prompts live in application code, usually as string constants or f-strings. One person owns them. Changes go out with deploys. This works fine until it doesn't.
The problems that accumulate are slow and hard to attribute:
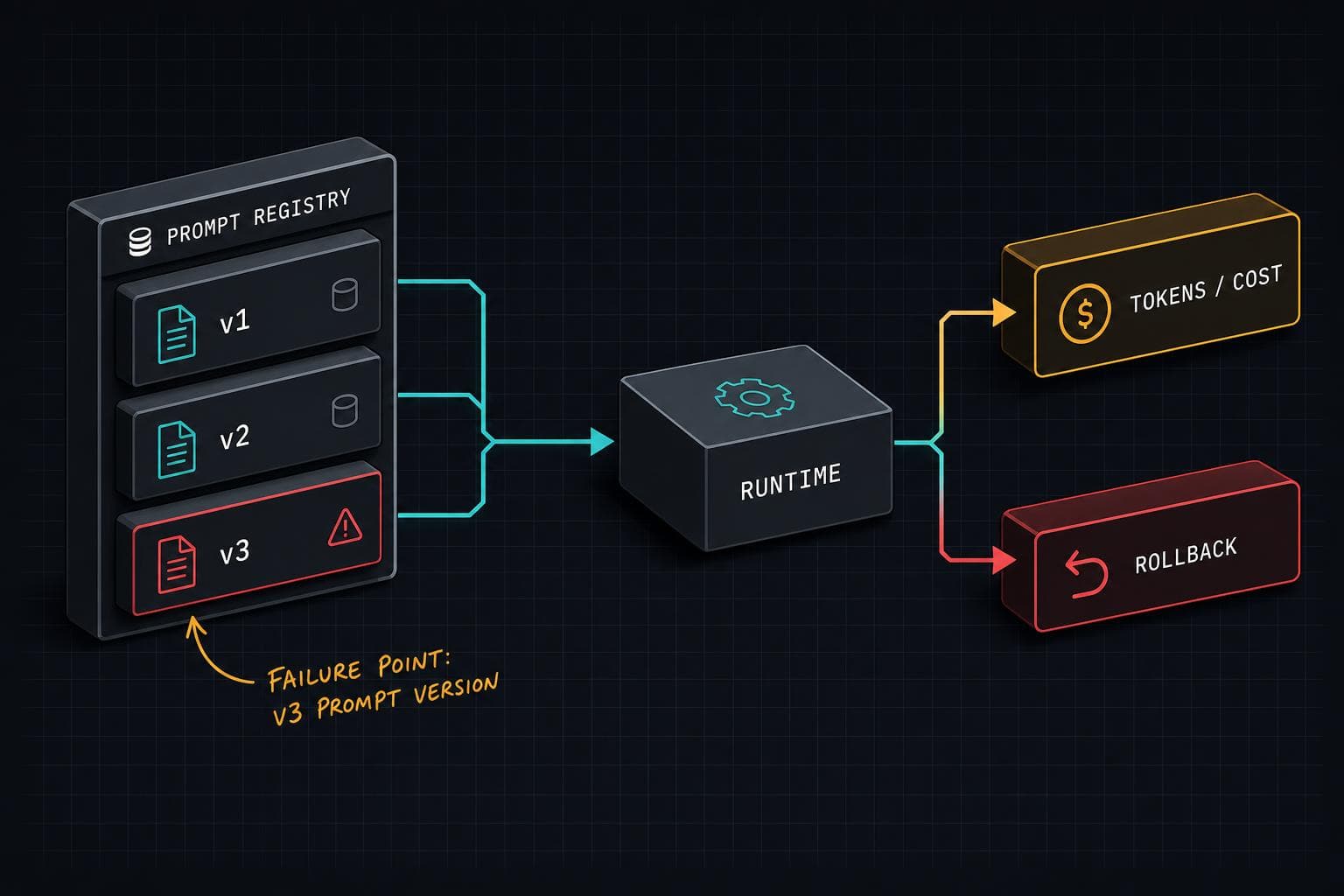
Reproducibility disappears. When a user reports degraded output, you can't answer "which prompt produced this response?" Git history tells you what changed, not what was running when. If prompts are embedded in code and you deploy twice a day, your blast radius for any given prompt change is invisible.
Cost creeps without a signal. Prompts grow. Few-shot examples get added. Context windows expand. As Datadog's State of AI Engineering report found, teams managing model fleets are dealing with prompt and retrieval changes that move latency and spend without an obvious code change. If you're not recording tokens-per-prompt-version, you won't notice that your monthly spend tripled until the bill arrives.
Rollback requires a deploy. When something breaks at 2am, the fastest fix is reverting to the last known-good prompt. If prompts live in your codebase, that means a full deploy cycle. If they live in a separate store, it's a config change.
What "Prompt Management" Actually Means in Practice
The phrase sounds like tooling. It's really a set of operational commitments.
The minimum viable version has three components:
A prompt store with versioning. Prompts live outside application code, in a system that assigns version IDs and records which version was active when. Every LLM response gets tagged with the prompt version that produced it. This is the foundation — without it, none of the other capabilities work. The implementation can be as simple as a database table with prompt_id, version, content, and deployed_at. The point is that the application fetches the prompt at runtime rather than baking it in at compile time.
Per-version cost and quality tracking. Every prompt version should accumulate token counts, latency, and whatever quality signal you have (thumbs up/down, downstream task success, LLM-as-judge scores). This turns cost visibility from a monthly surprise into a per-change signal. It also makes the "is this prompt actually better?" question answerable with data instead of intuition. The Antigravity post describes a case where a "more natural phrasing" dropped accuracy by 10% — caught only two weeks after deploy because there was no A/B mechanism in place.
Instant rollback. The prompt store should support flagging a version as inactive and promoting a previous version as current, without touching application code. This is the operational payoff. When something breaks, you need a path to recovery that doesn't involve waking up your deploy pipeline.
When to Build vs. When to Buy
For teams under 20 engineers with a handful of AI features, I'd argue a lightweight internal prompt store is the right call before reaching for a dedicated platform. The core data model is simple, you control the schema, and you avoid vendor lock-in on something that sits in your critical path.
The calculus shifts when you hit multi-model deployments. Datadog's report found that more than 70% of organizations now use three or more models. At that point, prompt management intersects with model routing — you need to know not just which prompt version ran, but which model it ran against, and whether the combination was the one you intended. That's where dedicated tooling like LangSmith or Weights & Biases Prompts starts earning its keep, because they instrument the full call chain rather than just the prompt text.
The forcing function is usually the first time you have two teams editing prompts for the same feature. At that point, "prompts in the codebase" stops being a minor inconvenience and becomes an active coordination problem.
Implementation Notes
Start with the simplest thing that gives you traceability. A prompt store doesn't need to be a product — it needs to answer "what prompt produced this output?" on demand. Build that first. Add A/B testing when you have enough traffic to make comparisons meaningful. Add automated quality evaluation when you have a quality signal worth tracking.
The one thing I'd do on day one: log the prompt version ID alongside every LLM response in your observability system. That single field is what makes every subsequent debugging session tractable.
Next week: What happens when your evaluation pipeline becomes the bottleneck — and why most teams build the wrong kind of evals first.


