The demo works. The agent researches a company, drafts a personalized email, and the team ships it. Three weeks later, you're getting paged because the agent is stuck in a retry loop, burning tokens, and the worker process died mid-run — taking twenty minutes of accumulated state with it.
That's not a model problem. That's an architecture problem. And it's the failure mode nobody talks about at the conference.
The Monolith Is the First Thing That Breaks
Most agents start as a single script. One big prompt, one loop, one LLM call trying to do everything. It works fine in development because development doesn't have API timeouts, rate limits, or the kind of ambiguous inputs that real users generate.
In production, the monolith fails silently. One sub-task hangs — a search API times out, the model hallucinates a malformed JSON response — and the whole pipeline stalls with no useful error signal. You don't know if it's stuck or just slow.
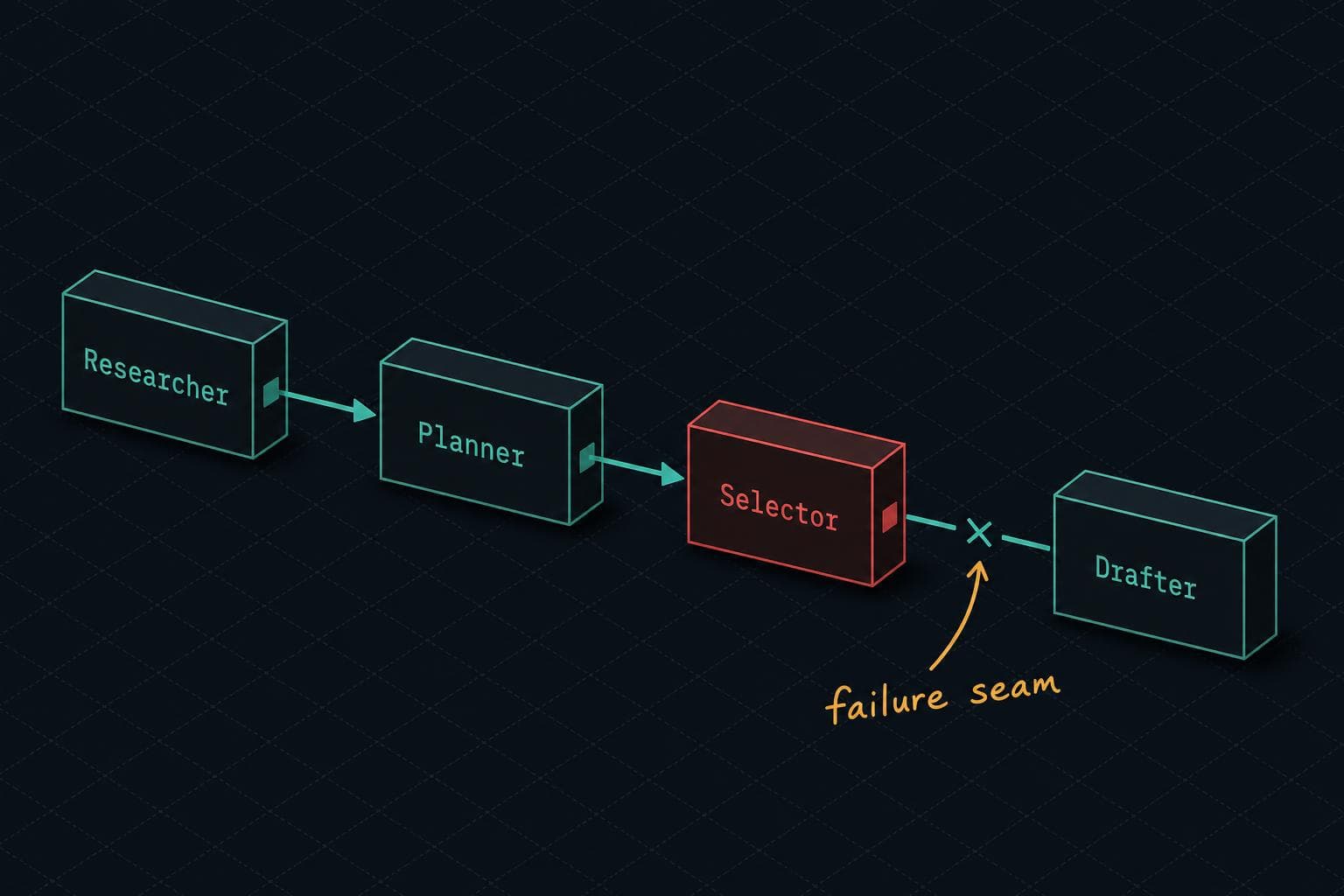
The Google Developers AI Agent Clinic documented exactly this pattern when they tore down a sales research agent called "Titanium." The original: a monolithic Python script running a linear for loop. When any sub-task failed, the entire process stalled. The fix was decomposition — splitting the work into a SequentialAgent pipeline with specialized nodes for research, planning, selection, and drafting. Each node has a narrow job. Each failure is isolated and observable.
The lesson isn't "use ADK" or any specific framework. The lesson is that separation of concerns matters more in agentic systems than in almost any other software you'll write, because the failure surface is so much wider.
Long-Running Agents Need Durable Execution, Not Just Retry Logic
Here's the failure mode that costs real money: an agent that runs for twenty minutes — making model calls, executing tool calls, accumulating state — crashes when the worker process dies. Everything restarts from zero. You paid for all those tokens twice.
The LangChain production runtime guide frames this precisely: unlike a web request that returns in milliseconds, an agent loop can span minutes or hours. A crash anywhere in that loop shouldn't erase prior work. What you need is resumption from the last completed step with state intact — not a retry that starts over.
This is a different problem than retry logic. Retries handle transient failures on individual calls. Durable execution handles infrastructure failures across a multi-step workflow. If your agent framework doesn't checkpoint state between steps, you're one deploy or worker restart away from a very expensive restart loop.
The same problem surfaces with human-in-the-loop workflows. An agent waiting for a human to approve a transaction doesn't know if that approval comes in thirty seconds or three days. Tying up a worker process for that window isn't viable. The agent needs to suspend, release the worker, and resume when the signal arrives. Most teams bolt this on after the first production incident. Build it in.
Scope Creep Kills More Agents Than Bad Models
The Data Science Collective analysis of what separates agents that deliver production value from those that don't is blunt: the winners have bounded scope. The agent handles one domain, with a defined tool set, and explicitly refuses tasks outside that boundary. The support agent handles tier-1 tickets. It doesn't touch billing.
This sounds obvious until you're in the sprint where someone asks "can we just have it also handle refund requests?" and the answer is yes, technically, but now you've doubled the failure surface and halved your ability to evaluate whether it's working correctly.
Datadog's State of AI Engineering report makes the operational version of this point: model, prompt, or retrieval changes can move latency, spend, and failure rates without an obvious code change. When your agent's scope is narrow, you can actually tell when something changed. When it's broad, you're debugging a distributed system where the failure could be anywhere.
The Trust Problem Is an Observability Problem
Honeycomb's post-webinar Q&A on AI agents in production has the most honest answer I've seen to the question of when you trust an agent enough to let it act autonomously: "It's a little bit vibes. I know that's not the answer people want."
But the follow-on is the useful part. Trust should work like onboarding a new engineer. You start with low-risk, well-understood tasks. You review everything. You widen the aperture as results are consistently good. The observability data is what lets you make that determination with evidence instead of gut feeling.
The practical implementation: innermost ring is changes where the agent can self-verify — runs tests, checks SLOs, confirms metrics didn't regress. Auto-merge only for categories where you've already validated this pattern. Next ring out: human review, but pre-annotated with observability context so the reviewer isn't starting from scratch.
That's not a model capability question. That's an operational discipline question. And it's the same question you'd ask about any system you're handing production access.
Next Week: We're going into cost attribution for multi-model workloads — specifically, why your LLM spend is probably being charged to the wrong service and what that means for optimization decisions.


